
compression.md 164 KB
Timescaledb - Compression
Pages: 19
Inserting or modifying data in the columnstore
URL: llms-txt#inserting-or-modifying-data-in-the-columnstore
Contents:
- Earlier versions of TimescaleDB (before v2.11.0)
In TimescaleDB [v2.11.0][tsdb-release-2-11-0] and later, you can use the UPDATE and DELETE
commands to modify existing rows in compressed chunks. This works in a similar
way to INSERT operations. To reduce the amount of decompression, TimescaleDB only attempts to decompress data where it is necessary.
However, if there are no qualifiers, or if the qualifiers cannot be used as filters, calls to UPDATE and DELETE may convert large amounts of data to the rowstore and back to the columnstore.
To avoid large scale conversion, filter on the columns you use to segementby and orderby. This filters as much data as possible before any data is modified, and reduces the amount of data conversions.
DML operations on the columnstore work if the data you are inserting has unique constraints. Constraints are preserved during the insert operation. TimescaleDB uses a Postgres function that decompresses relevant data during the insert to check if the new data breaks unique checks. This means that any time you insert data into the columnstore, a small amount of data is decompressed to allow a speculative insertion, and block any inserts which could violate constraints.
For TimescaleDB [v2.17.0][tsdb-release-2-17-0] and later, delete performance is improved on compressed
hypertables when a large amount of data is affected. When you delete whole segments of
data, filter your deletes by segmentby column(s) instead of separate deletes.
This considerably increases performance by skipping the decompression step.
Since TimescaleDB [v2.21.0][tsdb-release-2-21-0] and later, DELETE operations on the columnstore
are executed on the batch level, which allows more performant deletion of data of non-segmentby columns
and reduces IO usage.
Earlier versions of TimescaleDB (before v2.11.0)
This feature requires Postgres 14 or later
From TimescaleDB v2.3.0, you can insert data into compressed chunks with some
limitations. The primary limitation is that you can't insert data with unique
constraints. Additionally, newly inserted data needs to be compressed at the
same time as the data in the chunk, either by a running recompression policy, or
by using recompress_chunk manually on the chunk.
In TimescaleDB v2.2.0 and earlier, you cannot insert data into compressed chunks.
===== PAGE: https://docs.tigerdata.com/use-timescale/jobs/create-and-manage-jobs/ =====
timescaledb_information.jobs
URL: llms-txt#timescaledb_information.jobs
Contents:
- Samples
- Arguments
Shows information about all jobs registered with the automation framework.
Shows a job associated with the refresh policy for continuous aggregates:
Find all jobs related to compression policies (before TimescaleDB v2.20):
Find all jobs related to columnstore policies (TimescaleDB v2.20 and later):
|Name|Type| Description |
|-|-|--------------------------------------------------------------------------------------------------------------|
|job_id|INTEGER| The ID of the background job |
|application_name|TEXT| Name of the policy or job |
|schedule_interval|INTERVAL| The interval at which the job runs. Defaults to 24 hours |
|max_runtime|INTERVAL| The maximum amount of time the job is allowed to run by the background worker scheduler before it is stopped |
|max_retries|INTEGER| The number of times the job is retried if it fails |
|retry_period|INTERVAL| The amount of time the scheduler waits between retries of the job on failure |
|proc_schema|TEXT| Schema name of the function or procedure executed by the job |
|proc_name|TEXT| Name of the function or procedure executed by the job |
|owner|TEXT| Owner of the job |
|scheduled|BOOLEAN| Set to true to run the job automatically |
|fixed_schedule|BOOLEAN| Set to true for jobs executing at fixed times according to a schedule interval and initial start |
|config|JSONB| Configuration passed to the function specified by proc_name at execution time |
|next_start|TIMESTAMP WITH TIME ZONE| Next start time for the job, if it is scheduled to run automatically |
|initial_start|TIMESTAMP WITH TIME ZONE| Time the job is first run and also the time on which execution times are aligned for jobs with fixed schedules |
|hypertable_schema|TEXT| Schema name of the hypertable. Set to NULL for a job |
|hypertable_name|TEXT| Table name of the hypertable. Set to NULL for a job |
|check_schema|TEXT| Schema name of the optional configuration validation function, set when the job is created or updated |
|check_name|TEXT| Name of the optional configuration validation function, set when the job is created or updated |
===== PAGE: https://docs.tigerdata.com/api/informational-views/hypertables/ =====
Examples:
Example 1 (sql):
SELECT * FROM timescaledb_information.jobs;
job_id | 1001
application_name | Refresh Continuous Aggregate Policy [1001]
schedule_interval | 01:00:00
max_runtime | 00:00:00
max_retries | -1
retry_period | 01:00:00
proc_schema | _timescaledb_internal
proc_name | policy_refresh_continuous_aggregate
owner | postgres
scheduled | t
config | {"start_offset": "20 days", "end_offset": "10
days", "mat_hypertable_id": 2}
next_start | 2020-10-02 12:38:07.014042-04
hypertable_schema | _timescaledb_internal
hypertable_name | _materialized_hypertable_2
check_schema | _timescaledb_internal
check_name | policy_refresh_continuous_aggregate_check
Example 2 (sql):
SELECT * FROM timescaledb_information.jobs where application_name like 'Compression%';
-[ RECORD 1 ]-----+--------------------------------------------------
job_id | 1002
application_name | Compression Policy [1002]
schedule_interval | 15 days 12:00:00
max_runtime | 00:00:00
max_retries | -1
retry_period | 01:00:00
proc_schema | _timescaledb_internal
proc_name | policy_compression
owner | postgres
scheduled | t
config | {"hypertable_id": 3, "compress_after": "60 days"}
next_start | 2020-10-18 01:31:40.493764-04
hypertable_schema | public
hypertable_name | conditions
check_schema | _timescaledb_internal
check_name | policy_compression_check
Example 3 (sql):
SELECT * FROM timescaledb_information.jobs where application_name like 'Columnstore%';
-[ RECORD 1 ]-----+--------------------------------------------------
job_id | 1002
application_name | Columnstore Policy [1002]
schedule_interval | 15 days 12:00:00
max_runtime | 00:00:00
max_retries | -1
retry_period | 01:00:00
proc_schema | _timescaledb_internal
proc_name | policy_compression
owner | postgres
scheduled | t
config | {"hypertable_id": 3, "compress_after": "60 days"}
next_start | 2025-10-18 01:31:40.493764-04
hypertable_schema | public
hypertable_name | conditions
check_schema | _timescaledb_internal
check_name | policy_compression_check
Example 4 (sql):
SELECT * FROM timescaledb_information.jobs where application_name like 'User-Define%';
-[ RECORD 1 ]-----+------------------------------
job_id | 1003
application_name | User-Defined Action [1003]
schedule_interval | 01:00:00
max_runtime | 00:00:00
max_retries | -1
retry_period | 00:05:00
proc_schema | public
proc_name | custom_aggregation_func
owner | postgres
scheduled | t
config | {"type": "function"}
next_start | 2020-10-02 14:45:33.339885-04
hypertable_schema |
hypertable_name |
check_schema | NULL
check_name | NULL
-[ RECORD 2 ]-----+------------------------------
job_id | 1004
application_name | User-Defined Action [1004]
schedule_interval | 01:00:00
max_runtime | 00:00:00
max_retries | -1
retry_period | 00:05:00
proc_schema | public
proc_name | custom_retention_func
owner | postgres
scheduled | t
config | {"type": "function"}
next_start | 2020-10-02 14:45:33.353733-04
hypertable_schema |
hypertable_name |
check_schema | NULL
check_name | NULL
Low compression rate
URL: llms-txt#low-compression-rate
Low compression rates are often caused by [high cardinality][cardinality-blog] of the segment key. This means that the column you selected for grouping the rows during compression has too many unique values. This makes it impossible to group a lot of rows in a batch. To achieve better compression results, choose a segment key with lower cardinality.
===== PAGE: https://docs.tigerdata.com/_troubleshooting/dropping-chunks-times-out/ =====
Query time-series data tutorial - set up compression
URL: llms-txt#query-time-series-data-tutorial---set-up-compression
Contents:
- Compression setup
- Add a compression policy
- Taking advantage of query speedups
You have now seen how to create a hypertable for your NYC taxi trip data and query it. When ingesting a dataset like this is seldom necessary to update old data and over time the amount of data in the tables grows. Over time you end up with a lot of data and since this is mostly immutable you can compress it to save space and avoid incurring additional cost.
It is possible to use disk-oriented compression like the support offered by ZFS and Btrfs but since TimescaleDB is build for handling event-oriented data (such as time-series) it comes with support for compressing data in hypertables.
TimescaleDB compression allows you to store the data in a vastly more efficient format allowing up to 20x compression ratio compared to a normal Postgres table, but this is of course highly dependent on the data and configuration.
TimescaleDB compression is implemented natively in Postgres and does not require special storage formats. Instead it relies on features of Postgres to transform the data into columnar format before compression. The use of a columnar format allows better compression ratio since similar data is stored adjacently. For more details on how the compression format looks, you can look at the [compression design][compression-design] section.
A beneficial side-effect of compressing data is that certain queries are significantly faster since less data has to be read into memory.
- Connect to the Tiger Cloud service that contains the
dataset using, for example
psql. - Enable compression on the table and pick suitable segment-by and
order-by column using the
ALTER TABLEcommand:
Depending on the choice if segment-by and order-by column you can
get very different performance and compression ratio. To learn
more about how to pick the correct columns, see
[here][segment-by-columns].
You can manually compress all the chunks of the hypertable using
compress_chunkin this manner:You can also [automate compression][automatic-compression] by adding a [compression policy][add_compression_policy] which will be covered below.
Now that you have compressed the table you can compare the size of the dataset before and after compression:
This shows a significant improvement in data usage:
Add a compression policy
To avoid running the compression step each time you have some data to compress you can set up a compression policy. The compression policy allows you to compress data that is older than a particular age, for example, to compress all chunks that are older than 8 days:
Compression policies run on a regular schedule, by default once every day, which means that you might have up to 9 days of uncompressed data with the setting above.
You can find more information on compression policies in the [add_compression_policy][add_compression_policy] section.
Taking advantage of query speedups
Previously, compression was set up to be segmented by vendor_id column value.
This means fetching data by filtering or grouping on that column will be
more efficient. Ordering is also set to time descending so if you run queries
which try to order data with that ordering, you should see performance benefits.
For instance, if you run the query example from previous section:
You should see a decent performance difference when the dataset is compressed and when is decompressed. Try it yourself by running the previous query, decompressing the dataset and running it again while timing the execution time. You can enable timing query times in psql by running:
To decompress the whole dataset, run:
On an example setup, speedup performance observed was pretty significant, 700 ms when compressed vs 1,2 sec when decompressed.
Try it yourself and see what you get!
===== PAGE: https://docs.tigerdata.com/tutorials/blockchain-query/blockchain-compress/ =====
Examples:
Example 1 (sql):
ALTER TABLE rides
SET (
timescaledb.compress,
timescaledb.compress_segmentby='vendor_id',
timescaledb.compress_orderby='pickup_datetime DESC'
);
Example 2 (sql):
SELECT compress_chunk(c) from show_chunks('rides') c;
Example 3 (sql):
SELECT
pg_size_pretty(before_compression_total_bytes) as before,
pg_size_pretty(after_compression_total_bytes) as after
FROM hypertable_compression_stats('rides');
Example 4 (sql):
before | after
---------+--------
1741 MB | 603 MB
add_policies()
URL: llms-txt#add_policies()
Contents:
- Samples
- Required arguments
- Optional arguments
- Returns
Add refresh, compression, and data retention policies to a continuous aggregate in one step. The added compression and retention policies apply to the continuous aggregate, not to the original hypertable.
Experimental features could have bugs. They might not be backwards compatible, and could be removed in future releases. Use these features at your own risk, and do not use any experimental features in production.
add_policies() does not allow the schedule_interval for the continuous aggregate to be set, instead using a default value of 1 hour.
If you would like to set this add your policies manually (see [add_continuous_aggregate_policy][add_continuous_aggregate_policy]).
Given a continuous aggregate named example_continuous_aggregate, add three
policies to it:
- Regularly refresh the continuous aggregate to materialize data between 1 day and 2 days old.
- Compress data in the continuous aggregate after 20 days.
- Drop data in the continuous aggregate after 1 year.
Required arguments
|Name|Type|Description|
|-|-|-|
|relation|REGCLASS|The continuous aggregate that the policies should be applied to|
Optional arguments
|Name|Type|Description|
|-|-|-|
|if_not_exists|BOOL|When true, prints a warning instead of erroring if the continuous aggregate doesn't exist. Defaults to false.|
|refresh_start_offset|INTERVAL or INTEGER|The start of the continuous aggregate refresh window, expressed as an offset from the policy run time.|
|refresh_end_offset|INTERVAL or INTEGER|The end of the continuous aggregate refresh window, expressed as an offset from the policy run time. Must be greater than refresh_start_offset.|
|compress_after|INTERVAL or INTEGER|Continuous aggregate chunks are compressed if they exclusively contain data older than this interval.|
|drop_after|INTERVAL or INTEGER|Continuous aggregate chunks are dropped if they exclusively contain data older than this interval.|
For arguments that could be either an INTERVAL or an INTEGER, use an
INTERVAL if your time bucket is based on timestamps. Use an INTEGER if your
time bucket is based on integers.
Returns true if successful.
===== PAGE: https://docs.tigerdata.com/api/continuous-aggregates/create_materialized_view/ =====
Examples:
Example 1 (sql):
timescaledb_experimental.add_policies(
relation REGCLASS,
if_not_exists BOOL = false,
refresh_start_offset "any" = NULL,
refresh_end_offset "any" = NULL,
compress_after "any" = NULL,
drop_after "any" = NULL)
) RETURNS BOOL
Example 2 (sql):
SELECT timescaledb_experimental.add_policies(
'example_continuous_aggregate',
refresh_start_offset => '1 day'::interval,
refresh_end_offset => '2 day'::interval,
compress_after => '20 days'::interval,
drop_after => '1 year'::interval
);
About writing data
URL: llms-txt#about-writing-data
TimescaleDB supports writing data in the same way as Postgres, using INSERT,
UPDATE, INSERT ... ON CONFLICT, and DELETE.
TimescaleDB is optimized for running real-time analytics workloads on time-series data. For this reason, hypertables are optimized for inserts to the most recent time intervals. Inserting data with recent time values gives excellent performance. However, if you need to make frequent updates to older time intervals, you might see lower write throughput.
===== PAGE: https://docs.tigerdata.com/use-timescale/write-data/upsert/ =====
Decompression
URL: llms-txt#decompression
Contents:
- Decompress chunks manually
- Decompress individual chunks
- Decompress chunks by time
- Decompress chunks on more precise constraints
Old API since TimescaleDB v2.18.0 Replaced by convert_to_rowstore.
When compressing your data, you can reduce the amount of storage space used. But you should always leave some additional storage capacity. This gives you the flexibility to decompress chunks when necessary, for actions such as bulk inserts.
This section describes commands to use for decompressing chunks. You can filter by time to select the chunks you want to decompress.
Decompress chunks manually
Before decompressing chunks, stop any compression policy on the hypertable you are decompressing.
The database automatically recompresses your chunks in the next scheduled job.
If you accumulate a large amount of chunks that need to be compressed, the [troubleshooting guide][troubleshooting-oom-chunks] shows how to compress a backlog of chunks.
For more information on how to stop and run compression policies using alter_job(), see the [API reference][api-reference-alter-job].
There are several methods for selecting chunks and decompressing them.
Decompress individual chunks
To decompress a single chunk by name, run this command:
where, <chunk_name> is the name of the chunk you want to decompress.
Decompress chunks by time
To decompress a set of chunks based on a time range, you can use the output of
show_chunks to decompress each one:
For more information about the decompress_chunk function, see the decompress_chunk
[API reference][api-reference-decompress].
Decompress chunks on more precise constraints
If you want to use more precise matching constraints, for example space partitioning, you can construct a command like this:
===== PAGE: https://docs.tigerdata.com/use-timescale/compression/compression-on-continuous-aggregates/ =====
Examples:
Example 1 (sql):
SELECT decompress_chunk('_timescaledb_internal.<chunk_name>');
Example 2 (sql):
SELECT decompress_chunk(c, true)
FROM show_chunks('table_name', older_than, newer_than) c;
Example 3 (sql):
SELECT tableoid::regclass FROM metrics
WHERE time = '2000-01-01' AND device_id = 1
GROUP BY tableoid;
tableoid
------------------------------------------
_timescaledb_internal._hyper_72_37_chunk
Designing your database for compression
URL: llms-txt#designing-your-database-for-compression
Contents:
- Compressing data
- Querying compressed data
Old API since TimescaleDB v2.18.0 Replaced by hypercore.
Time-series data can be unique, in that it needs to handle both shallow and wide queries, such as "What's happened across the deployment in the last 10 minutes," and deep and narrow, such as "What is the average CPU usage for this server over the last 24 hours." Time-series data usually has a very high rate of inserts as well; hundreds of thousands of writes per second can be very normal for a time-series dataset. Additionally, time-series data is often very granular, and data is collected at a higher resolution than many other datasets. This can result in terabytes of data being collected over time.
All this means that if you need great compression rates, you probably need to consider the design of your database, before you start ingesting data. This section covers some of the things you need to take into consideration when designing your database for maximum compression effectiveness.
TimescaleDB is built on Postgres which is, by nature, a row-based database. Because time-series data is accessed in order of time, when you enable compression, TimescaleDB converts many wide rows of data into a single row of data, called an array form. This means that each field of that new, wide row stores an ordered set of data comprising the entire column.
For example, if you had a table with data that looked a bit like this:
|Timestamp|Device ID|Status Code|Temperature| |-|-|-|-| |12:00:01|A|0|70.11| |12:00:01|B|0|69.70| |12:00:02|A|0|70.12| |12:00:02|B|0|69.69| |12:00:03|A|0|70.14| |12:00:03|B|4|69.70|
You can convert this to a single row in array form, like this:
|Timestamp|Device ID|Status Code|Temperature| |-|-|-|-| |[12:00:01, 12:00:01, 12:00:02, 12:00:02, 12:00:03, 12:00:03]|[A, B, A, B, A, B]|[0, 0, 0, 0, 0, 4]|[70.11, 69.70, 70.12, 69.69, 70.14, 69.70]|
Even before you compress any data, this format immediately saves storage by reducing the per-row overhead. Postgres typically adds a small number of bytes of overhead per row. So even without any compression, the schema in this example is now smaller on disk than the previous format.
This format arranges the data so that similar data, such as timestamps, device IDs, or temperature readings, is stored contiguously. This means that you can then use type-specific compression algorithms to compress the data further, and each array is separately compressed. For more information about the compression methods used, see the [compression methods section][compression-methods].
When the data is in array format, you can perform queries that require a subset of the columns very quickly. For example, if you have a query like this one, that asks for the average temperature over the past day:
now() - interval ‘1 day’ ORDER BY minute DESC GROUP BY minute; `} />
The query engine can fetch and decompress only the timestamp and temperature columns to efficiently compute and return these results.
Finally, TimescaleDB uses non-inline disk pages to store the compressed arrays. This means that the in-row data points to a secondary disk page that stores the compressed array, and the actual row in the main table becomes very small, because it is now just pointers to the data. When data stored like this is queried, only the compressed arrays for the required columns are read from disk, further improving performance by reducing disk reads and writes.
Querying compressed data
In the previous example, the database has no way of knowing which rows need to be fetched and decompressed to resolve a query. For example, the database can't easily determine which rows contain data from the past day, as the timestamp itself is in a compressed column. You don't want to have to decompress all the data in a chunk, or even an entire hypertable, to determine which rows are required.
TimescaleDB automatically includes more information in the row and includes
additional groupings to improve query performance. When you compress a
hypertable, either manually or through a compression policy, it can help to specify
an ORDER BY column.
ORDER BY columns specify how the rows that are part of a compressed batch are
ordered. For most time-series workloads, this is by timestamp, so if you don't
specify an ORDER BY column, TimescaleDB defaults to using the time column. You
can also specify additional dimensions, such as location.
For each ORDER BY column, TimescaleDB automatically creates additional columns
that store the minimum and maximum value of that column. This way, the query
planner can look at the range of timestamps in the compressed column, without
having to do any decompression, and determine whether the row could possibly
match the query.
When you compress your hypertable, you can also choose to specify a SEGMENT BY
column. This allows you to segment compressed rows by a specific column, so that
each compressed row corresponds to a data about a single item such as, for
example, a specific device ID. This further allows the query planner to
determine if the row could possibly match the query without having to decompress
the column first. For example:
|Device ID|Timestamp|Status Code|Temperature|Min Timestamp|Max Timestamp| |-|-|-|-|-|-| |A|[12:00:01, 12:00:02, 12:00:03]|[0, 0, 0]|[70.11, 70.12, 70.14]|12:00:01|12:00:03| |B|[12:00:01, 12:00:02, 12:00:03]|[0, 0, 4]|[69.70, 69.69, 69.70]|12:00:01|12:00:03|
With the data segmented in this way, a query for device A between a time interval becomes quite fast. The query planner can use an index to find those rows for device A that contain at least some timestamps corresponding to the specified interval, and even a sequential scan is quite fast since evaluating device IDs or timestamps does not require decompression. This means the query executor only decompresses the timestamp and temperature columns corresponding to those selected rows.
===== PAGE: https://docs.tigerdata.com/use-timescale/compression/compression-policy/ =====
remove_compression_policy()
URL: llms-txt#remove_compression_policy()
Contents:
- Samples
- Required arguments
- Optional arguments
Old API since TimescaleDB v2.18.0 Replaced by remove_columnstore_policy().
If you need to remove the compression policy. To restart policy-based compression you need to add the policy again. To view the policies that already exist, see [informational views][informational-views].
Remove the compression policy from the 'cpu' table:
Remove the compression policy from the 'cpu_weekly' continuous aggregate:
Required arguments
|Name|Type|Description|
|-|-|-|
|hypertable|REGCLASS|Name of the hypertable or continuous aggregate the policy should be removed from|
Optional arguments
| Name | Type | Description |
|---|---|---|
if_exists |
BOOLEAN | Setting to true causes the command to fail with a notice instead of an error if a compression policy does not exist on the hypertable. Defaults to false. |
===== PAGE: https://docs.tigerdata.com/api/compression/alter_table_compression/ =====
Examples:
Example 1 (unknown):
Remove the compression policy from the 'cpu_weekly' continuous aggregate:
About compression methods
URL: llms-txt#about-compression-methods
Contents:
- Integer compression
- Delta encoding
- Delta-of-delta encoding
- Simple-8b
- Run-length encoding
- Floating point compression
- XOR-based compression
- Data-agnostic compression
- Dictionary compression
Depending on the data type that is compressed when your data is converted from the rowstore to the columnstore, TimescaleDB uses the following compression algorithms:
- Integers, timestamps, boolean and other integer-like types: a combination of the following compression methods is used: [delta encoding][delta], [delta-of-delta][delta-delta], [simple-8b][simple-8b], and [run-length encoding][run-length].
- Columns that do not have a high amount of repeated values: [XOR-based][xor] compression with some [dictionary compression][dictionary].
- All other types: [dictionary compression][dictionary].
This page gives an in-depth explanation of the compression methods used in hypercore.
Integer compression
For integers, timestamps, and other integer-like types TimescaleDB uses a combination of delta encoding, delta-of-delta, simple 8-b, and run-length encoding.
The simple-8b compression method has been extended so that data can be decompressed in reverse order. Backward scanning queries are common in time-series workloads. This means that these types of queries run much faster.
Delta encoding reduces the amount of information required to represent a data object by only storing the difference, sometimes referred to as the delta, between that object and one or more reference objects. These algorithms work best where there is a lot of redundant information, and it is often used in workloads like versioned file systems. For example, this is how Dropbox keeps your files synchronized. Applying delta-encoding to time-series data means that you can use fewer bytes to represent a data point, because you only need to store the delta from the previous data point.
For example, imagine you had a dataset that collected CPU, free memory, temperature, and humidity over time. If you time column was stored as an integer value, like seconds since UNIX epoch, your raw data would look a little like this:
|time|cpu|mem_free_bytes|temperature|humidity| |-|-|-|-|-| |2023-04-01 10:00:00|82|1,073,741,824|80|25| |2023-04-01 10:00:05|98|858,993,459|81|25| |2023-04-01 10:00:10|98|858,904,583|81|25|
With delta encoding, you only need to store how much each value changed from the previous data point, resulting in smaller values to store. So after the first row, you can represent subsequent rows with less information, like this:
|time|cpu|mem_free_bytes|temperature|humidity| |-|-|-|-|-| |2023-04-01 10:00:00|82|1,073,741,824|80|25| |5 seconds|16|-214,748,365|1|0| |5 seconds|0|-88,876|0|0|
Applying delta encoding to time-series data takes advantage of the fact that most time-series datasets are not random, but instead represent something that is slowly changing over time. The storage savings over millions of rows can be substantial, especially if the value changes very little, or doesn't change at all.
Delta-of-delta encoding
Delta-of-delta encoding takes delta encoding one step further and applies delta-encoding over data that has previously been delta-encoded. With time-series datasets where data collection happens at regular intervals, you can apply delta-of-delta encoding to the time column, which results in only needing to store a series of zeroes.
In other words, delta encoding stores the first derivative of the dataset, while delta-of-delta encoding stores the second derivative of the dataset.
Applied to the example dataset from earlier, delta-of-delta encoding results in this:
|time|cpu|mem_free_bytes|temperature|humidity| |-|-|-|-|-| |2020-04-01 10:00:00|82|1,073,741,824|80|25| |5 seconds|16|-214,748,365|1|0| |0 seconds|0|-88,876|0|0|
In this example, delta-of-delta further compresses 5 seconds in the time column down to 0 for every entry in the time column after the second row, because the five second gap remains constant for each entry. Note that you see two entries in the table before the delta-delta 0 values, because you need two deltas to compare.
This compresses a full timestamp of 8 bytes, or 64 bits, down to just a single bit, resulting in 64x compression.
With delta and delta-of-delta encoding, you can significantly reduce the number of digits you need to store. But you still need an efficient way to store the smaller integers. The previous examples used a standard integer datatype for the time column, which needs 64 bits to represent the value of 0 when delta-delta encoded. This means that even though you are only storing the integer 0, you are still consuming 64 bits to store it, so you haven't actually saved anything.
Simple-8b is one of the simplest and smallest methods of storing variable-length integers. In this method, integers are stored as a series of fixed-size blocks. For each block, every integer within the block is represented by the minimal bit-length needed to represent the largest integer in that block. The first bits of each block denotes the minimum bit-length for the block.
This technique has the advantage of only needing to store the length once for a given block, instead of once for each integer. Because the blocks are of a fixed size, you can infer the number of integers in each block from the size of the integers being stored.
For example, if you wanted to store a temperature that changed over time, and you applied delta encoding, you might end up needing to store this set of integers:
|temperature (deltas)| |-| |1| |10| |11| |13| |9| |100| |22| |11|
With a block size of 10 digits, you could store this set of integers as two blocks: one block storing 5 2-digit numbers, and a second block storing 3 3-digit numbers, like this:
In this example, both blocks store about 10 digits worth of data, even though some of the numbers have to be padded with a leading 0. You might also notice that the second block only stores 9 digits, because 10 is not evenly divisible by 3.
Simple-8b works in this way, except it uses binary numbers instead of decimal, and it usually uses 64-bit blocks. In general, the longer the integer, the fewer number of integers that can be stored in each block.
Run-length encoding
Simple-8b compresses integers very well, however, if you have a large number of repeats of the same value, you can get even better compression with run-length encoding. This method works well for values that don't change very often, or if an earlier transformation removes the changes.
Run-length encoding is one of the classic compression algorithms. For time-series data with billions of contiguous zeroes, or even a document with a million identically repeated strings, run-length encoding works incredibly well.
For example, if you wanted to store a temperature that changed minimally over time, and you applied delta encoding, you might end up needing to store this set of integers:
|temperature (deltas)| |-| |11| |12| |12| |12| |12| |12| |12| |1| |12| |12| |12| |12|
For values like these, you do not need to store each instance of the value, but
rather how long the run, or number of repeats, is. You can store this set of
numbers as {run; value} pairs like this:
This technique uses 11 digits of storage (1, 1, 1, 6, 1, 2, 1, 1, 4, 1, 2), rather than 23 digits that an optimal series of variable-length integers requires (11, 12, 12, 12, 12, 12, 12, 1, 12, 12, 12, 12).
Run-length encoding is also used as a building block for many more advanced algorithms, such as Simple-8b RLE, which is an algorithm that combines run-length and Simple-8b techniques. TimescaleDB implements a variant of Simple-8b RLE. This variant uses different sizes to standard Simple-8b, in order to handle 64-bit values, and RLE.
Floating point compression
For columns that do not have a high amount of repeated values, TimescaleDB uses XOR-based compression.
The standard XOR-based compression method has been extended so that data can be decompressed in reverse order. Backward scanning queries are common in time-series workloads. This means that queries that use backwards scans run much faster.
XOR-based compression
Floating point numbers are usually more difficult to compress than integers. Fixed-length integers often have leading zeroes, but floating point numbers usually use all of their available bits, especially if they are converted from decimal numbers, which can't be represented precisely in binary.
Techniques like delta-encoding don't work well for floats, because they do not reduce the number of bits sufficiently. This means that most floating-point compression algorithms tend to be either complex and slow, or truncate significant digits. One of the few simple and fast lossless floating-point compression algorithms is XOR-based compression, built on top of Facebook's Gorilla compression.
XOR is the binary function exclusive or. In this algorithm, successive
floating point numbers are compared with XOR, and a difference results in a bit
being stored. The first data point is stored without compression, and subsequent
data points are represented using their XOR'd values.
Data-agnostic compression
For values that are not integers or floating point, TimescaleDB uses dictionary compression.
Dictionary compression
One of the earliest lossless compression algorithms, dictionary compression is the basis of many popular compression methods. Dictionary compression can also be found in areas outside of computer science, such as medical coding.
Instead of storing values directly, dictionary compression works by making a list of the possible values that can appear, and then storing an index into a dictionary containing the unique values. This technique is quite versatile, can be used regardless of data type, and works especially well when you have a limited set of values that repeat frequently.
For example, if you had the list of temperatures shown earlier, but you wanted an additional column storing a city location for each measurement, you might have a set of values like this:
|City| |-| |New York| |San Francisco| |San Francisco| |Los Angeles|
Instead of storing all the city names directly, you can instead store a dictionary, like this:
You can then store just the indices in your column, like this:
|City| |-| |0| |1| |1| |2|
For a dataset with a lot of repetition, this can offer significant compression. In the example, each city name is on average 11 bytes in length, while the indices are never going to be more than 4 bytes long, reducing space usage nearly 3 times. In TimescaleDB, the list of indices is compressed even further with the Simple-8b+RLE method, making the storage cost even smaller.
Dictionary compression doesn't always result in savings. If your dataset doesn't have a lot of repeated values, then the dictionary is the same size as the original data. TimescaleDB automatically detects this case, and falls back to not using a dictionary in that scenario.
===== PAGE: https://docs.tigerdata.com/use-timescale/compression/modify-a-schema/ =====
Changelog
URL: llms-txt#changelog
Contents:
- TimescaleDB 2.22.1 – configurable indexing, enhanced partitioning, and faster queries
- Highlighted features
- Deprecations
- Kafka Source Connector (beta)
- Phased update rollouts,
pg_cron, larger compute options, and backup reports- 🛡️ Phased rollouts for TimescaleDB minor releases
- ⏰ pg_cron extension
- ⚡️ Larger compute options: 48 and 64 CPU
- 📋 Backup report for compliance
- 🗺️ New router for Tiger Cloud Console
All the latest features and updates to Tiger Cloud.
TimescaleDB 2.22.1 – configurable indexing, enhanced partitioning, and faster queries
October 10, 2025
TimescaleDB 2.22.1 introduces major performance and flexibility improvements across indexing, compression, and query execution. TimescaleDB 2.22.1 was released on September 30th and is now available to all users of Tiger.
Highlighted features
Configurable sparse indexes: manually configure sparse indexes (min-max or bloom) on one or more columns of compressed hypertables, optimizing query performance for specific workloads and reducing I/O. In previous versions, these were automatically created based on heuristics and could not be modified.
UUIDv7 support: native support for UUIDv7 for both compression and partitioning. UUIDv7 embeds a time component, improving insert locality and enabling efficient time-based range queries while maintaining global uniqueness.
Vectorized UUID compression: new vectorized compression for UUIDv7 columns doubles query performance and improves storage efficiency by up to 30%.
UUIDv7 partitioning: hypertables can now be partitioned on UUIDv7 columns, combining time-based chunking with globally unique IDs—ideal for large-scale event and log data.
Multi-column SkipScan: expands SkipScan to support multiple distinct keys, delivering millisecond-fast deduplication and
DISTINCT ONqueries across billions of rows. Learn more in our blog post and documentation.Compression improvements: default
segmentbyandorderbysettings are now applied at compression time for each chunk, automatically adapting to evolving data patterns for better performance. This was previously set at the hypertable level and fixed across all chunks.
The experimental Hypercore Table Access Method (TAM) has been removed in this release following advancements in the columnstore architecture.
For a comprehensive list of changes, refer to the TimescaleDB 2.22 & 2.22.1 release notes.
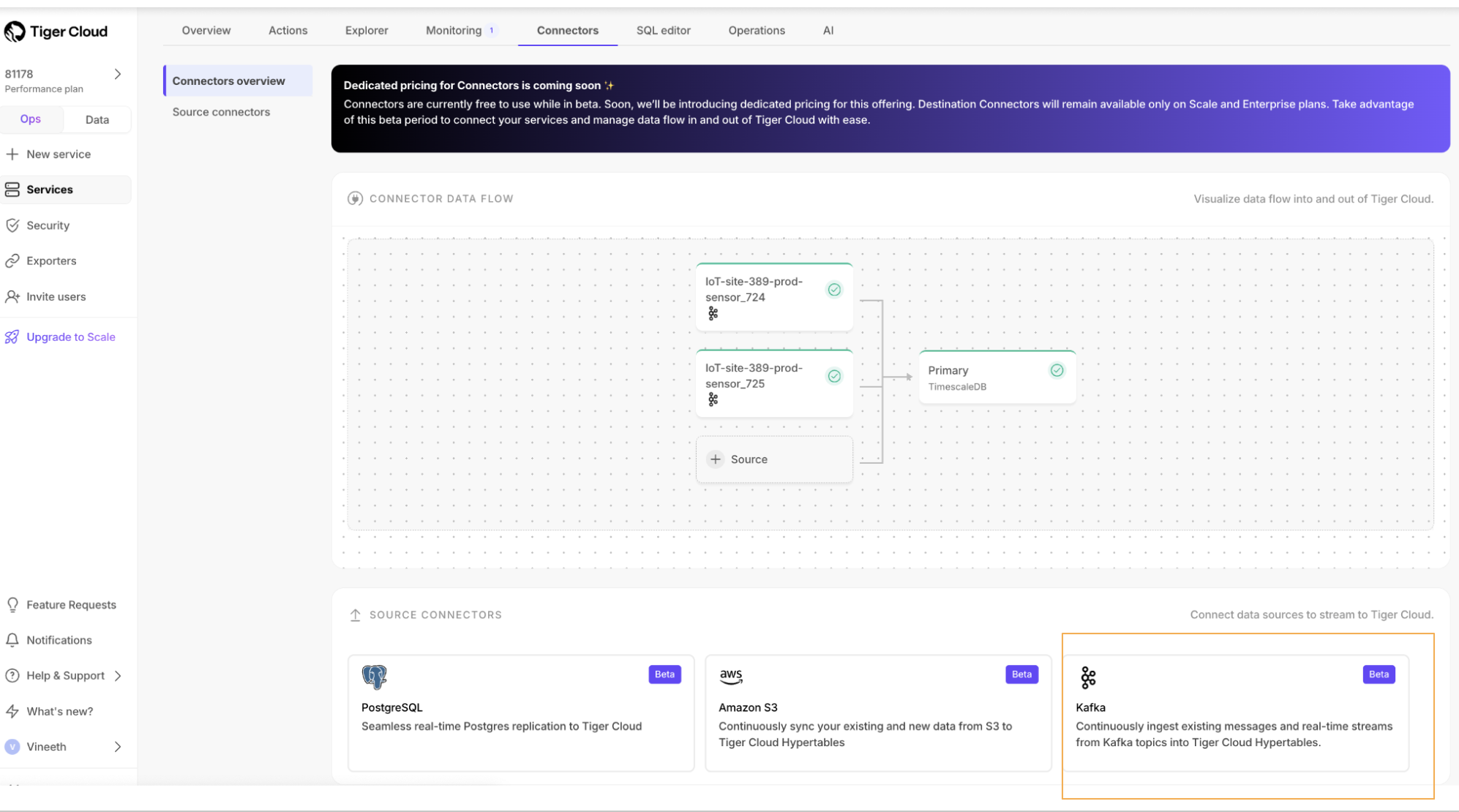
Kafka Source Connector (beta)
September 19, 2025
The new Kafka Source Connector enables you to connect your existing Kafka clusters directly to Tiger Cloud and ingest data from Kafka topics into hypertables. Developers often build proxies or run JDBC Sink Connectors to bridge Kafka and Tiger Cloud, which is error-prone and time-consuming. With the Kafka Source Connector, you can seamlessly start ingesting your Kafka data natively without additional middleware.
- Supported formats: AVRO
- Supported platforms: Confluent Cloud and Amazon Managed Streaming for Apache Kafka
Phased update rollouts, pg_cron, larger compute options, and backup reports
September 12, 2025
🛡️ Phased rollouts for TimescaleDB minor releases
Starting with TimescaleDB 2.22.0, minor releases will now roll out in phases. Services tagged #dev will get upgraded first, followed by #prod after 21 days. This gives you time to validate upgrades in #dev before they reach #prod services. Subscribe to get an email notification before your #prod service is upgraded. See Maintenance and upgrades for details.
⏰ pg_cron extension
pg_cron is now available on Tiger Cloud! With pg_cron, you can:
- Schedule SQL commands to run automatically—like generating weekly sales reports or cleaning up old log entries every night at 2 AM.
- Automate routine maintenance tasks such as refreshing materialized views hourly to keep dashboards current.
- Eliminate external cron jobs and task schedulers, keeping all your automation logic within PostgreSQL.
To enable pg_cron on your service, contact our support team. We're working on making this self-service in future updates.
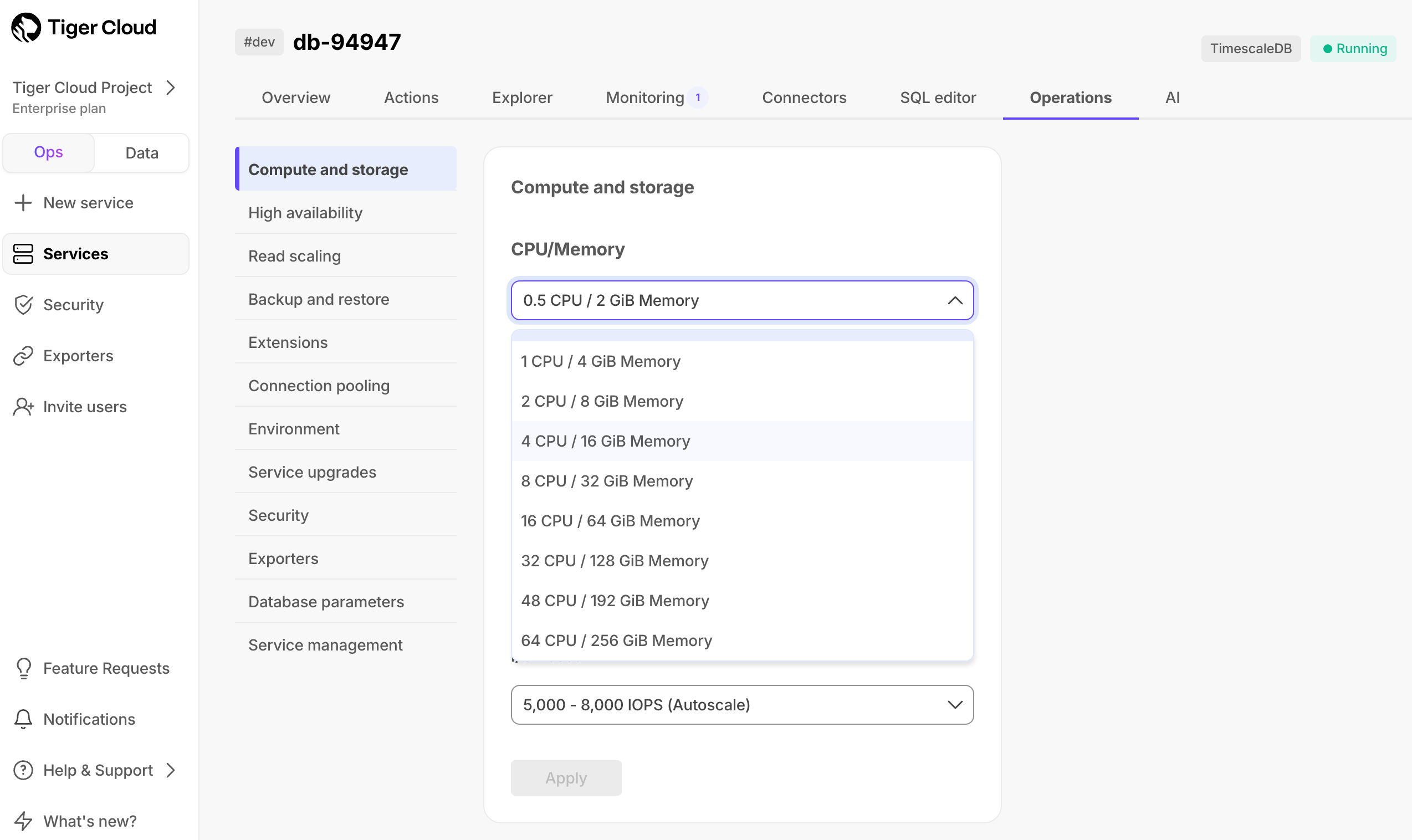
⚡️ Larger compute options: 48 and 64 CPU
For the most demanding workloads, you can now create services with 48 and 64 CPUs. These options are only available on our Enterprise plan, and they're dedicated instances that are not shared with other customers.
📋 Backup report for compliance
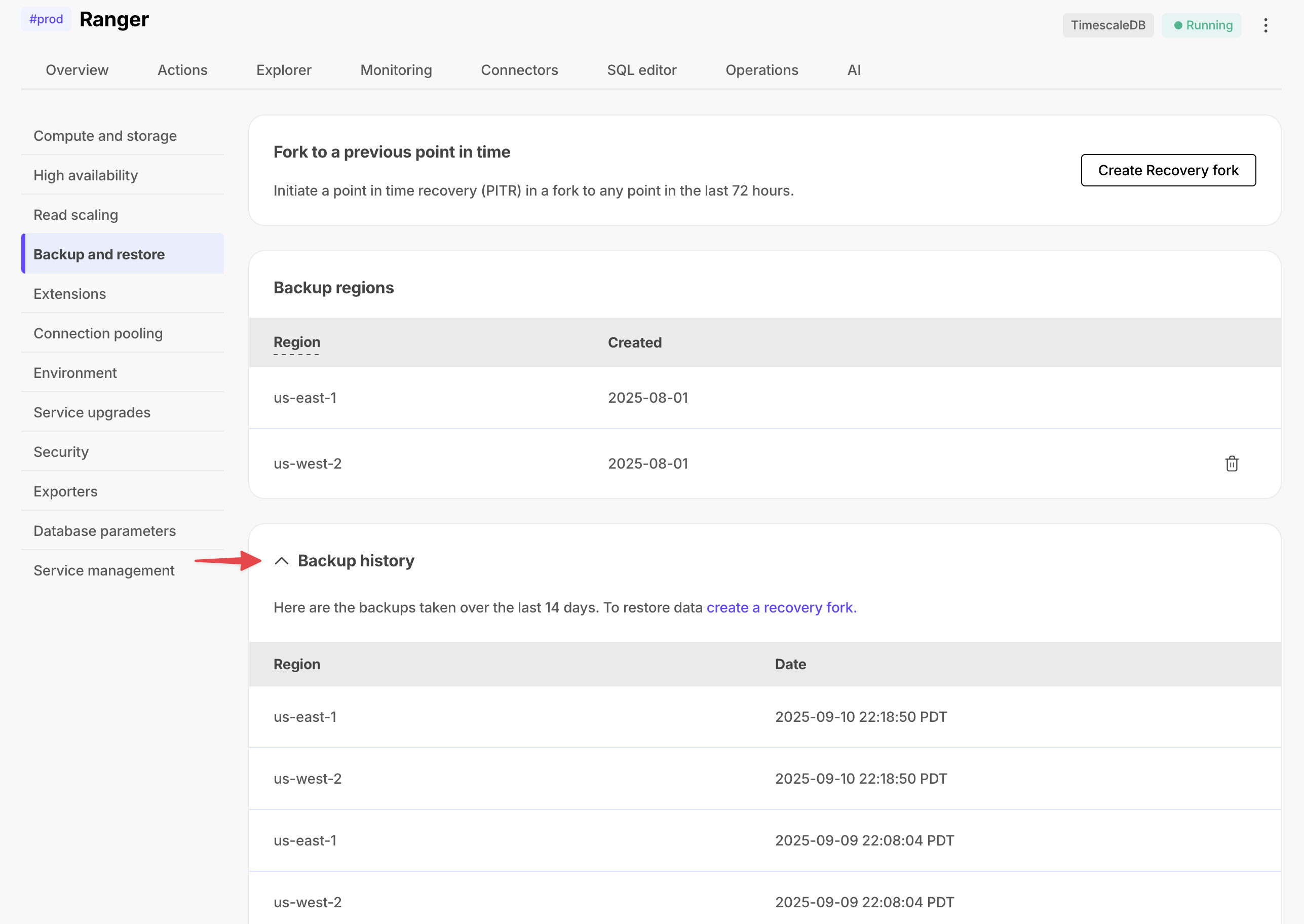
Scale and Enterprise customers can now see a list of their backups in Tiger Cloud Console. For customers with SOC 2 or other compliance needs, this serves as auditable proof of backups.
🗺️ New router for Tiger Cloud Console
The UI just got snappier and easier to navigate with improved interlinking. For example, click an object in the Jobs page to see what hypertable the job is associated with.
New data import wizard
September 5, 2025
To make navigation easier, we’ve introduced a cleaner, more intuitive UI for data import. It highlights the most common and recommended option, PostgreSQL Dump & Restore, while organizing all import options into clear categories, to make navigation easier.
The new categories include:
- PostgreSQL Dump & Restore
- Upload Files: CSV, Parquet, TXT
- Real-time Data Replication: source connectors
- Migrations & Other Options
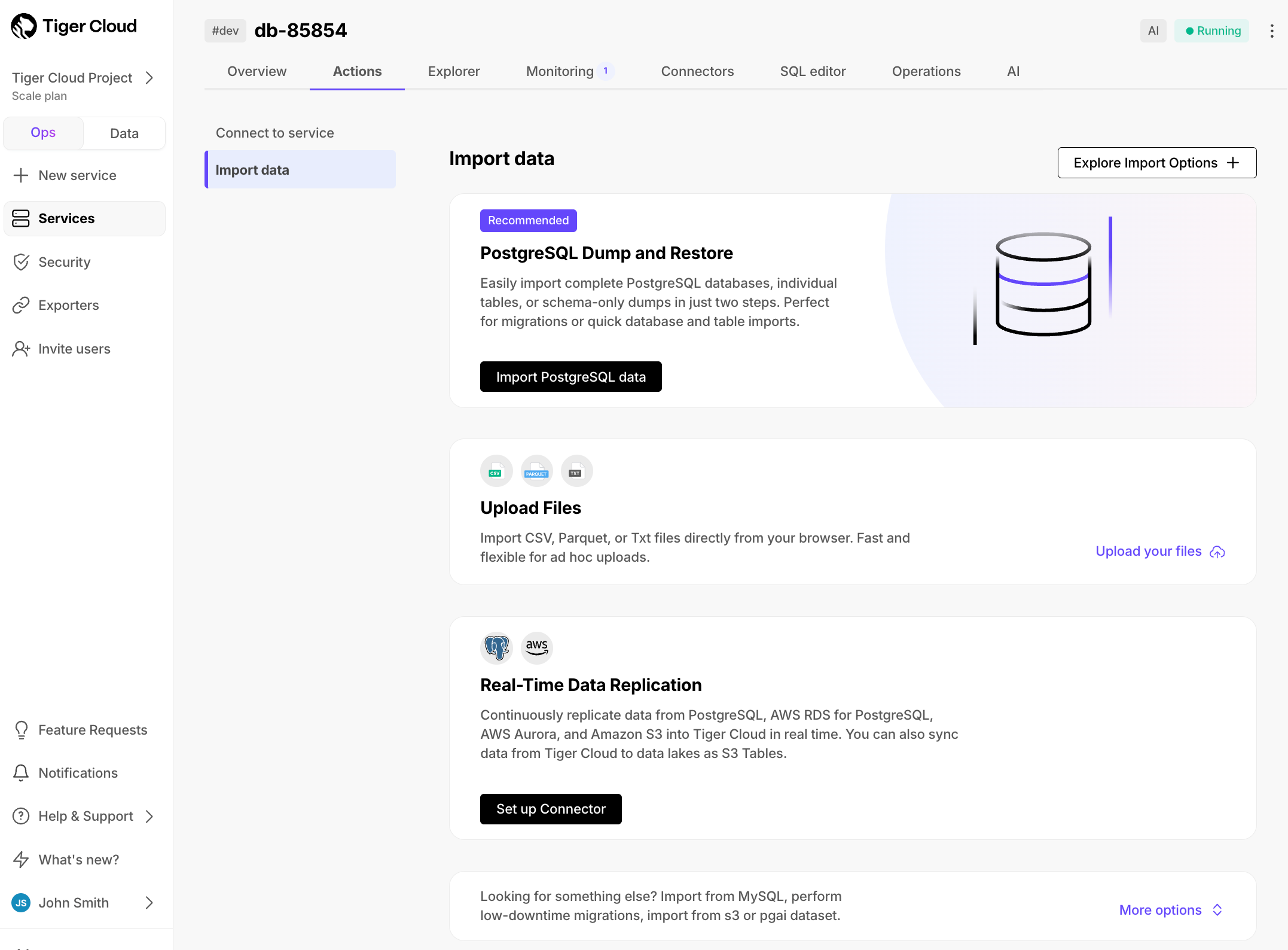
A new data import component has been added to the overview dashboard, providing a clear view of your imports. This includes quick start, in-progress status, and completed imports:
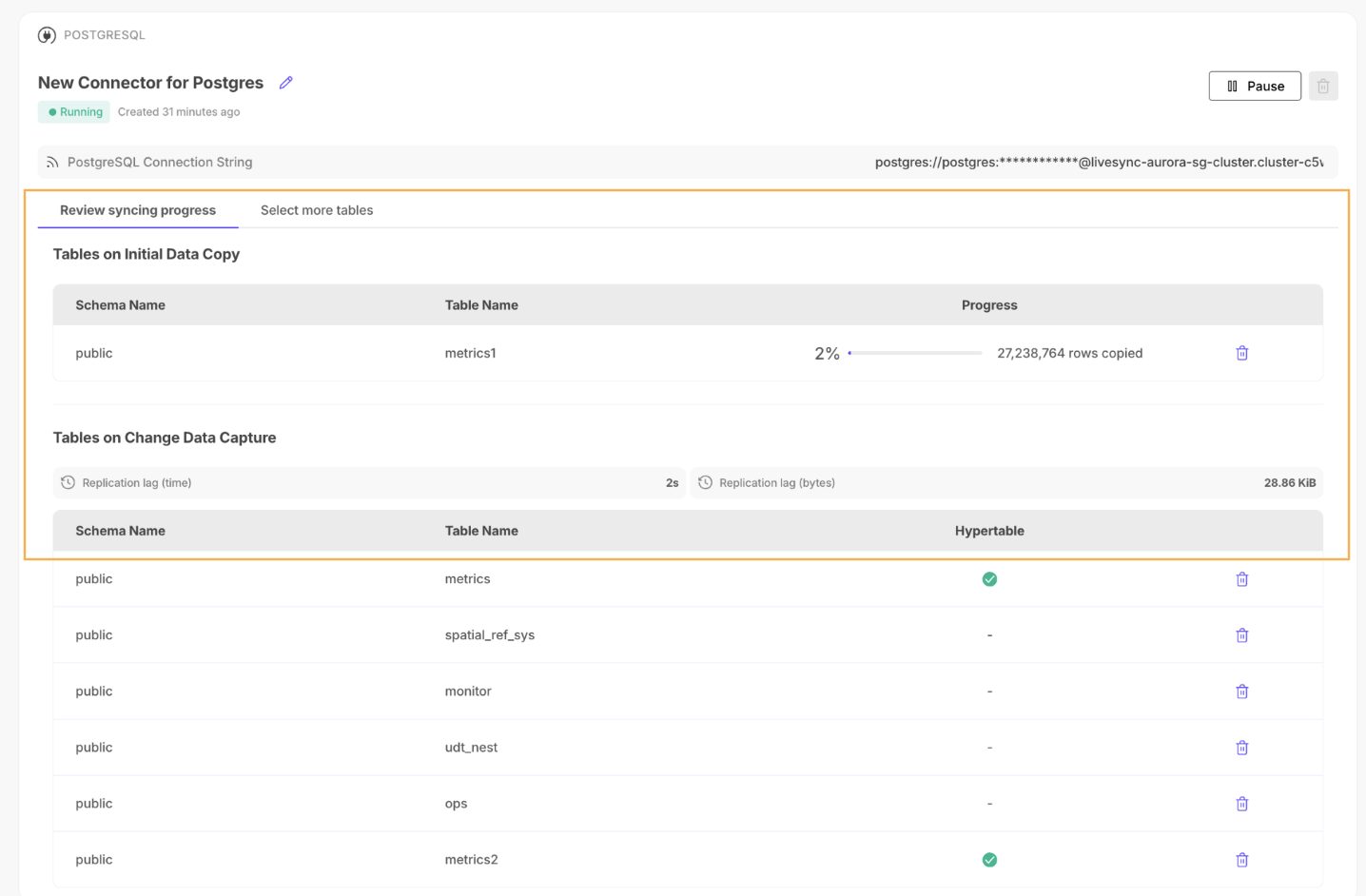
🚁 Enhancements to the Postgres source connector
August 28, 2025
- Easy table selection: You can now sync the complete source schema in one go. Select multiple tables from the drop-down menu and start the connector.
- Sync metadata: Connectors now display the following detailed metadata:
Initial data copy: The number of rows copied at any given point in time.Change data capture: The replication lag represented in time and data size.
- Improved UX design: In-progress syncs with separate sections showing the tables and metadata for
initial data copyandchange data capture, plus a dedicated tab where you can add more tables to the connector.
🦋 Developer role GA and hypertable transformation in Console
August 21, 2025
Developer role (GA)
The Developer role in Tiger Cloud is now generally available. It’s a project‑scoped permission set that lets technical users build and operate services, create or modify resources, run queries, and use observability—without admin or billing access. This enforces least‑privilege by default, reducing risk and audit noise, while keeping governance with Admins/Owners and billing with Finance. This means faster delivery (fewer access escalations), protected sensitive settings, and clear boundaries, so the right users can ship changes safely, while compliance and cost control remain intact.
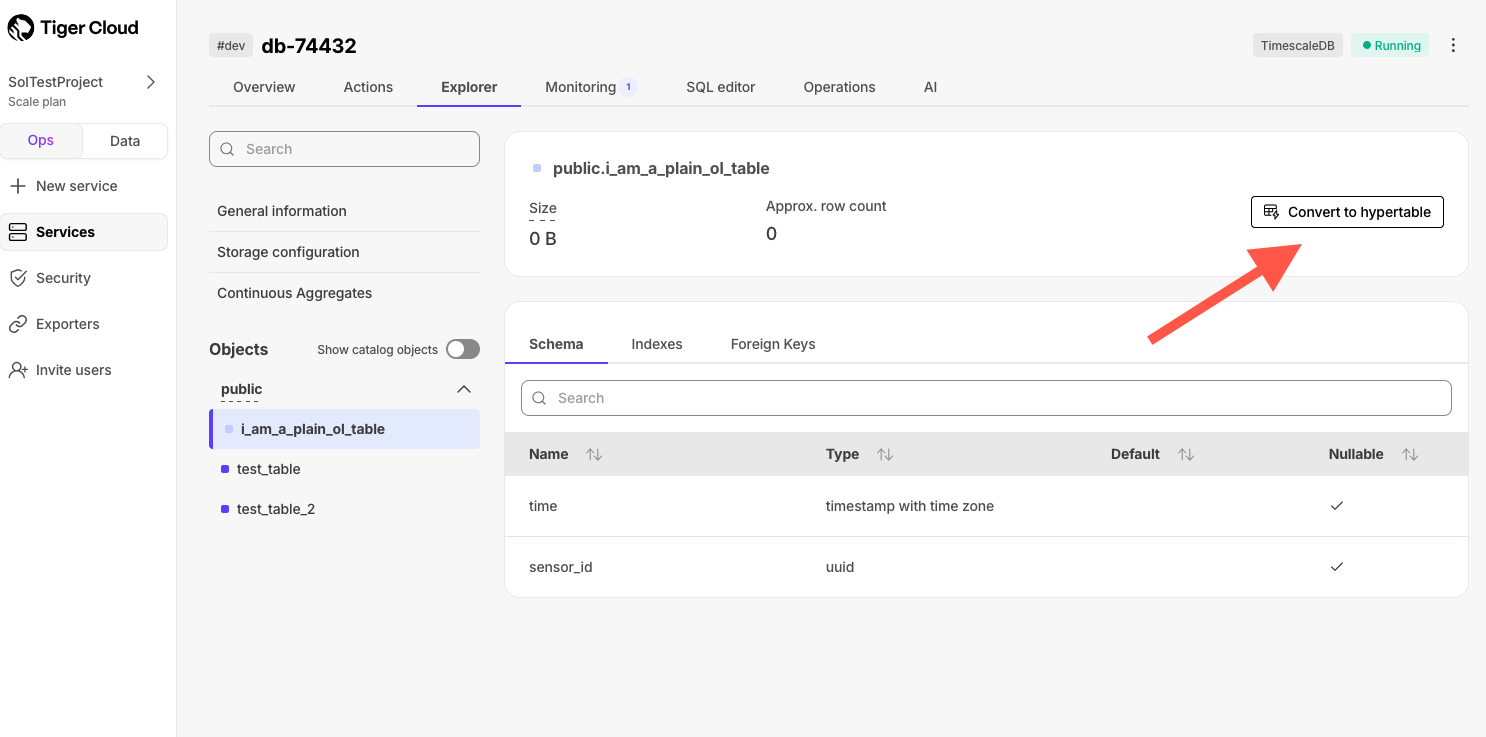
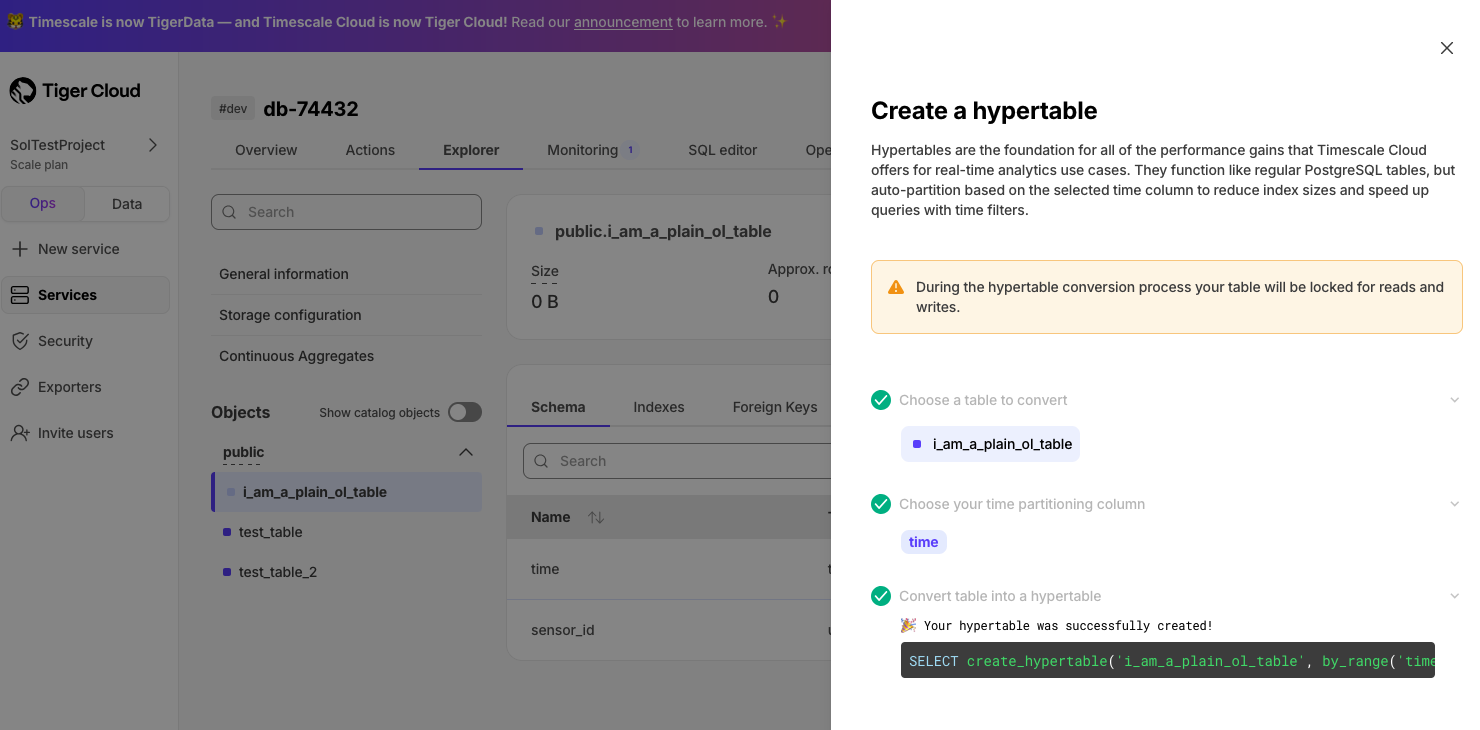
Transform a table to a hypertable from the Explorer
In Console, you can now easily create hypertables from your regular Postgres tables directly from the Explorer. Clicking on any Postgres table shows an option to open up the hypertable action. Follow the simple steps to set up your partition key and transform the table to a hypertable.
Cross-region backups, Postgres options, and onboarding
August 14, 2025
Cross-region backups
You can now store backups in a different region than your service, which improves resilience and helps meet enterprise compliance requirements. Cross‑region backups are available on our Enterprise plan for free at launch; usage‑based billing may be introduced later. For full details, please see the docs.
Standard Postgres instructions for onboarding
We have added basic instructions for INSERT, UPDATE, DELETE commands to the Tiger Cloud console. It's now shown as an option in the Import Data page.
Postgres-only service type
In Tiger Cloud, you now have an option to choose Postgres-only in the service creation flow. Just click Looking for plan PostgreSQL? on the Service Type screen.
Viewer role GA, EXPLAIN plans, and chunk index sizes in Explorer
July 31, 2025
GA release of the viewer role in role-based access
The viewer role is now generally available for all projects and organizations. It provides read-only access to services, metrics, and logs without modify permissions. Viewers cannot create, update, or delete resources, nor manage users or billing. It's ideal for auditors, analysts, and cross-functional collaborators who need visibility but not control.
EXPLAIN plans in Insights
You can now find automatically generated EXPLAIN plans on queries that take longer than 10 seconds within Insights. EXPLAIN plans can be very useful to determine how you may be able to increase the performance of your queries.
Chunk index size in Explorer
Find the index size of hypertable chunks in the Explorer. This information can be very valuable to determine if a hypertable's chunk size is properly configured.
TimescaleDB v2.21 and catalog objects in the Console Explorer
July 25, 2025
🏎️ TimescaleDB v2.21—ingest millions of rows/second and faster columnstore UPSERTs and DELETEs
TimescaleDB v2.21 was released on July 8 and is now available to all developers on Tiger Cloud.
Highlighted features in TimescaleDB v2.21 include:
- High-scale ingestion performance (tech preview): introducing a new approach that compresses data directly into the columnstore during ingestion, demonstrating over 1.2M rows/second in tests with bursts over 50M rows/second. We are actively seeking design partners for this feature.
- Faster data updates (UPSERTs): columnstore UPSERTs are now 2.5x faster for heavily constrained tables, building on the 10x improvement from v2.20.
- Faster data deletion: DELETE operations on non-segmentby columns are 42x faster, reducing I/O and bloat.
- Reduced bloat after recompression: optimized recompression processes lead to less bloat and more efficient storage.
- Enhanced continuous aggregates:
- Concurrent refresh policies enable multiple continuous aggregates to update concurrently.
- Batched refreshes are now enabled by default for more efficient processing.
- Complete chunk management: full support for splitting columnstore chunks, complementing the existing merge capabilities.
For a comprehensive list of changes, refer to the TimescaleDB v2.21 release notes.
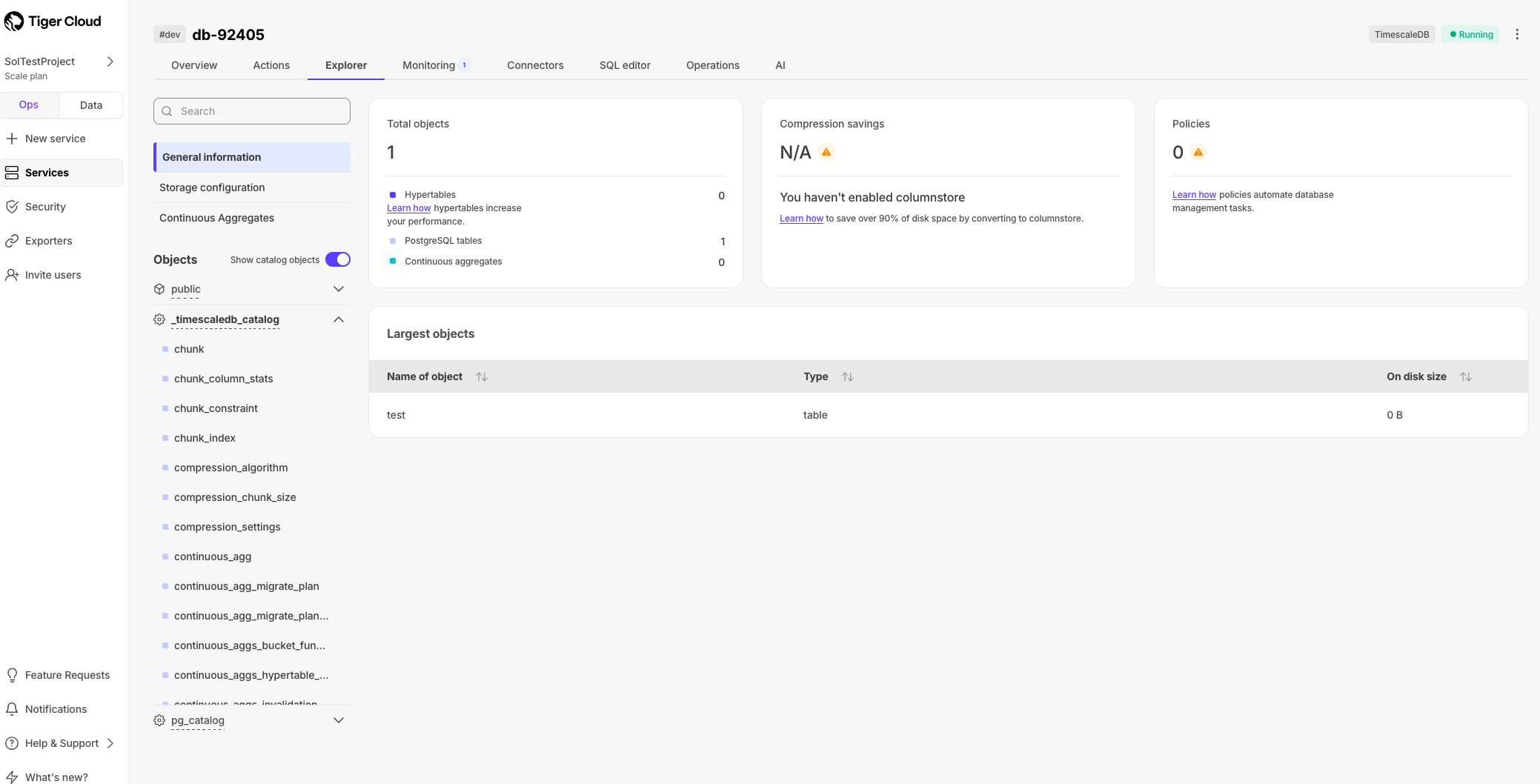
🔬 Catalog objects available in the Console Explorer
You can now view catalog objects in the Console Explorer. Check out the internal schemas for PostgreSQL and TimescaleDB to better understand the inner workings of your database. To turn on/off visibility, select your service in Tiger Cloud Console, then click Explorer and toggle Show catalog objects.
Iceberg Destination Connector (Tiger Lake)
July 18, 2025
We have released a beta Iceberg destination connector that enables Scale and Enterprise users to integrate Tiger Cloud services with Amazon S3 tables. This enables you to connect Tiger Cloud to data lakes seamlessly. We are actively developing several improvements that will make the overall data lake integration process even smoother.
To use this feature, select your service in Tiger Cloud Console, then navigate to Connectors and select the Amazon S3 Tables destination connector. Integrate the connector to your S3 table bucket by providing the ARN roles, then simply select the tables that you want to sync into S3 tables. See the documentation for details.
🔆Console just got better
July 11, 2025
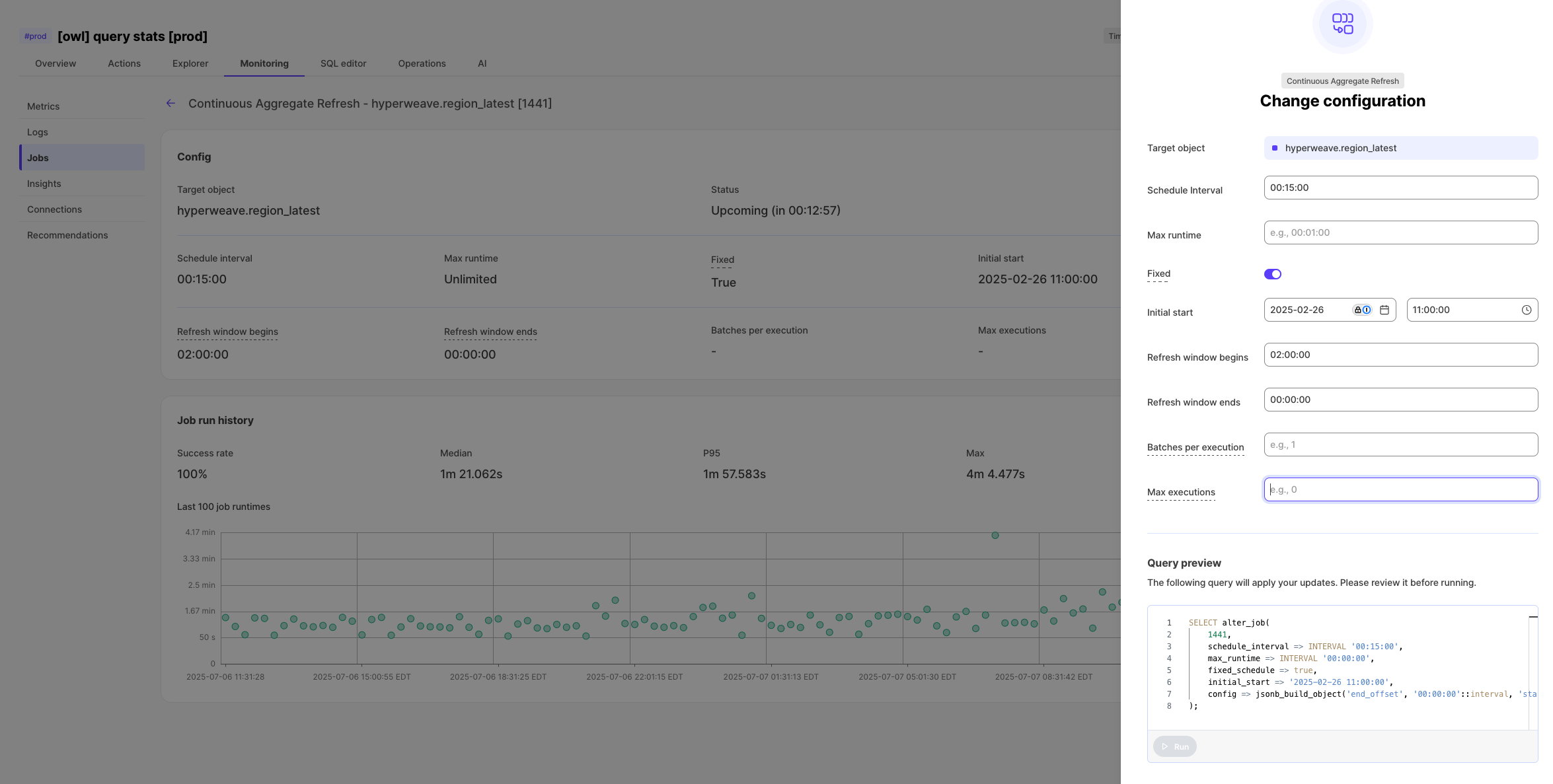
✏️ Editable jobs in Console
You can now edit jobs directly in Console! We've added the handy pencil icon in the top right corner of any job view. Click a job, hit the edit button, then make your changes. This works for all jobs, even user-defined ones. Tiger Cloud jobs come with custom wizards to guide you through the right inputs. This means you can spot and fix issues without leaving the UI - a small change that makes a big difference!
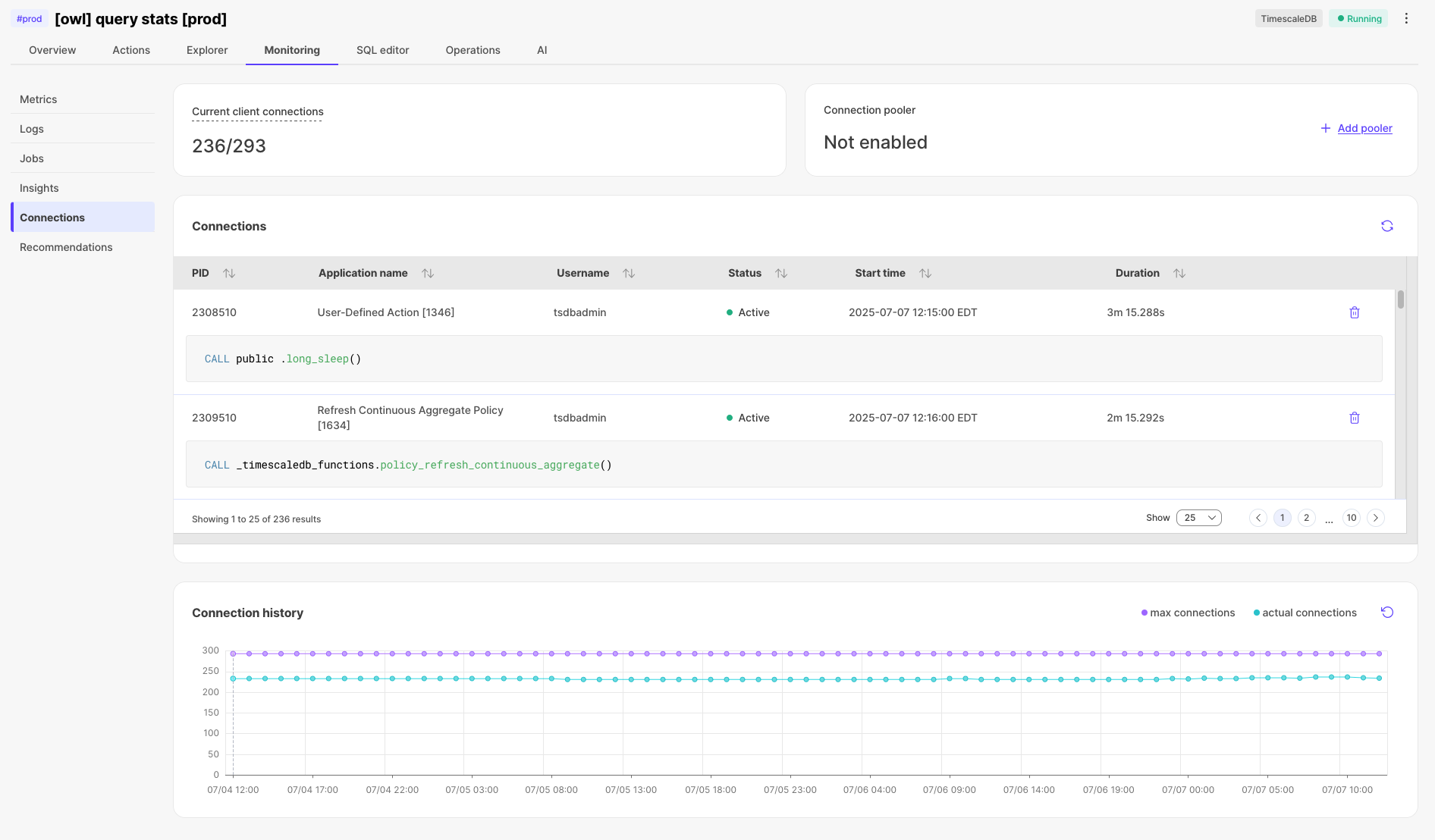
📊 Connection history
Now you can see your historical connection counts right in the Connections tab! This helps spot those pesky connection management bugs before they impact your app. We're logging max connections every hour (sampled every 5 mins) and might adjust based on your feedback. Just another way we're making the Console more powerful for troubleshooting.
🔐 New in Public Beta: Read-Only Access through RBAC
We’ve just launched Read/Viewer-only access for Tiger Cloud projects into public beta!
You can now invite users with view-only permissions — perfect for folks who need to see dashboards, metrics, and query results, without the ability to make changes.
This has been one of our most requested RBAC features, and it's a big step forward in making Tiger Cloud more secure and collaborative.
No write access. No config changes. Just visibility.
In Console, Go to Project Settings > Users & Roles to try it out, and let us know what you think!
👀 Super useful doc updates
July 4, 2025
Updates to instructions for livesync
In the Console UI, we have clarified the step-by-step procedure for setting up your livesync from self-hosted installations by:
- Adding definitions for some flags when running your Docker container.
- Including more detailed examples of the output from the table synchronization list.
New optional argument for add_continuous_aggregate_policy API
Added the new refresh_newest_first optional argument that controls the order of incremental refreshes.
🚀 Multi-command queries in SQL editor, improved job page experience, multiple AWS Transit Gateways, and a new service creation flow
June 20, 2025
Run multiple statements in SQL editor
Execute complex queries with multiple commands in a single run—perfect for data transformations, table setup, and batch operations.
Branch conversations in SQL assistant
Start new discussion threads from any point in your SQL assistant chat to explore different approaches to your data questions more easily.
Smarter results table
- Expand JSON data instantly: turn complex JSON objects into readable columns with one click—no more digging through nested data structures.
- Filter with precision: use a new smart filter to pick exactly what you want from a dropdown of all available values.
Jobs page improvements
Individual job pages now display their corresponding configuration for TimescaleDB job types—for example, columnstore, retention, CAgg refreshes, tiering, and others.
Multiple AWS Transit Gateways
You can now connect multiple AWS Transit Gateways, when those gateways use overlapping CIDRs. Ideal for teams with zero-trust policies, this lets you keep each network path isolated.
How it works: when you create a new peering connection, Tiger Cloud reuses the existing Transit Gateway if you supply the same ID—otherwise it automatically creates a new, isolated Transit Gateway.
Updated service creation flow
The new service creation flow makes the choice of service type clearer. You can now create distinct types with Postgres extensions for real-time analytics (TimescaleDB), AI (pgvectorscale, pgai), and RTA/AI hybrid applications.
⚙️ Improved Terraform support and TimescaleDB v2.20.3
June 13, 2025
Terraform support for Exporters and AWS Transit Gateway
The latest version of the Timescale Terraform provider (2.3.0) adds support for:
- Creating and attaching observability exporters to your services.
- Securing the connections to your Timescale Cloud services with AWS Transit Gateway.
- Configuring CIDRs for VPC and AWS Transit Gateway connections.
Check the Timescale Terraform provider documentation for more details.
TimescaleDB v2.20.3
This patch release for TimescaleDB v2.20 includes several bug fixes and minor improvements. Notable bug fixes include:
- Adjustments to SkipScan costing for queries that require a full scan of indexed data.
- A fix for issues encountered during dump and restore operations when chunk skipping is enabled.
- Resolution of a bug related to dropped "quals" (qualifications/conditions) in SkipScan.
For a comprehensive list of changes, refer to the TimescaleDB 2.20.3 release notes.
🧘 Read replica sets, faster tables, new anthropic models, and VPC support in data mode
June 6, 2025
Horizontal read scaling with read replica sets
Read replica sets are an improved version of read replicas. They let you scale reads horizontally by creating up to 10 replica nodes behind a single read endpoint. Just point your read queries to the endpoint and configure the number of replicas you need without changing your application logic. You can increase or decrease the number of replicas in the set dynamically, with no impact on the endpoint.
Read replica sets are used to:
- Scale reads for read-heavy workloads and dashboards.
- Isolate internal analytics and reporting from customer-facing applications.
- Provide high availability and fault tolerance for read traffic.
All existing read replicas have been automatically upgraded to a replica set with one node—no action required. Billing remains the same.
Read replica sets are available for all Scale and Enterprise customers.
Faster, smarter results tables in data mode
We've completely rebuilt how query results are displayed in the data mode to give you a faster, more powerful way to work with your data. The new results table can handle millions of rows with smooth scrolling and instant responses when you sort, filter, or format your data. You'll find it today in notebooks and presentation pages, with more areas coming soon.
- Your settings stick around: when you customize how your table looks—applying filters, sorting columns, or formatting data—those settings are automatically saved. Switch to another tab and come back, and everything stays exactly how you left it.
- Better ways to find what you need: filter your results by any column value, with search terms highlighted so you can quickly spot what you're looking for. The search box is now available everywhere you work with data.
- Export exactly what you want: download your entire table or just select the specific rows and columns you need. Both CSV and Excel formats are supported.
- See patterns in your data: highlight cells based on their values to quickly spot trends, outliers, or important thresholds in your results.
- Smoother navigation: click any row number to see the full details in an expanded view. Columns automatically resize to show your data clearly, and web links in your results are now clickable.
As a result, working with large datasets is now faster and more intuitive. Whether you're exploring millions of rows or sharing results with your team, the new table keeps up with how you actually work with data.
Latest anthropic models added to SQL assistant
Data mode's SQL assistant now supports Anthropic's latest models:
- Sonnet 4
- Sonnet 4 (extended thinking)
- Opus 4
- Opus 4 (extended thinking)
VPC support for passwordless data mode connections
We previously made it much easier to connect newly created services to Timescale’s data mode. We have now expanded this functionality to services using a VPC.
🕵🏻️ Enhanced service monitoring, TimescaleDB v2.20, and livesync for Postgres
May 30, 2025
Updated top-level navigation - Monitoring tab
In Timescale Console, we have consolidated multiple top-level service information tabs into the single Monitoring tab.
This tab houses information previously displayed in the Recommendations, Jobs, Connections, Metrics, Logs,
and Insights tabs.
Monitor active connections
In the Connections section under Monitoring, you can now see information like the query being run, the application
name, and duration for all current connections to a service.
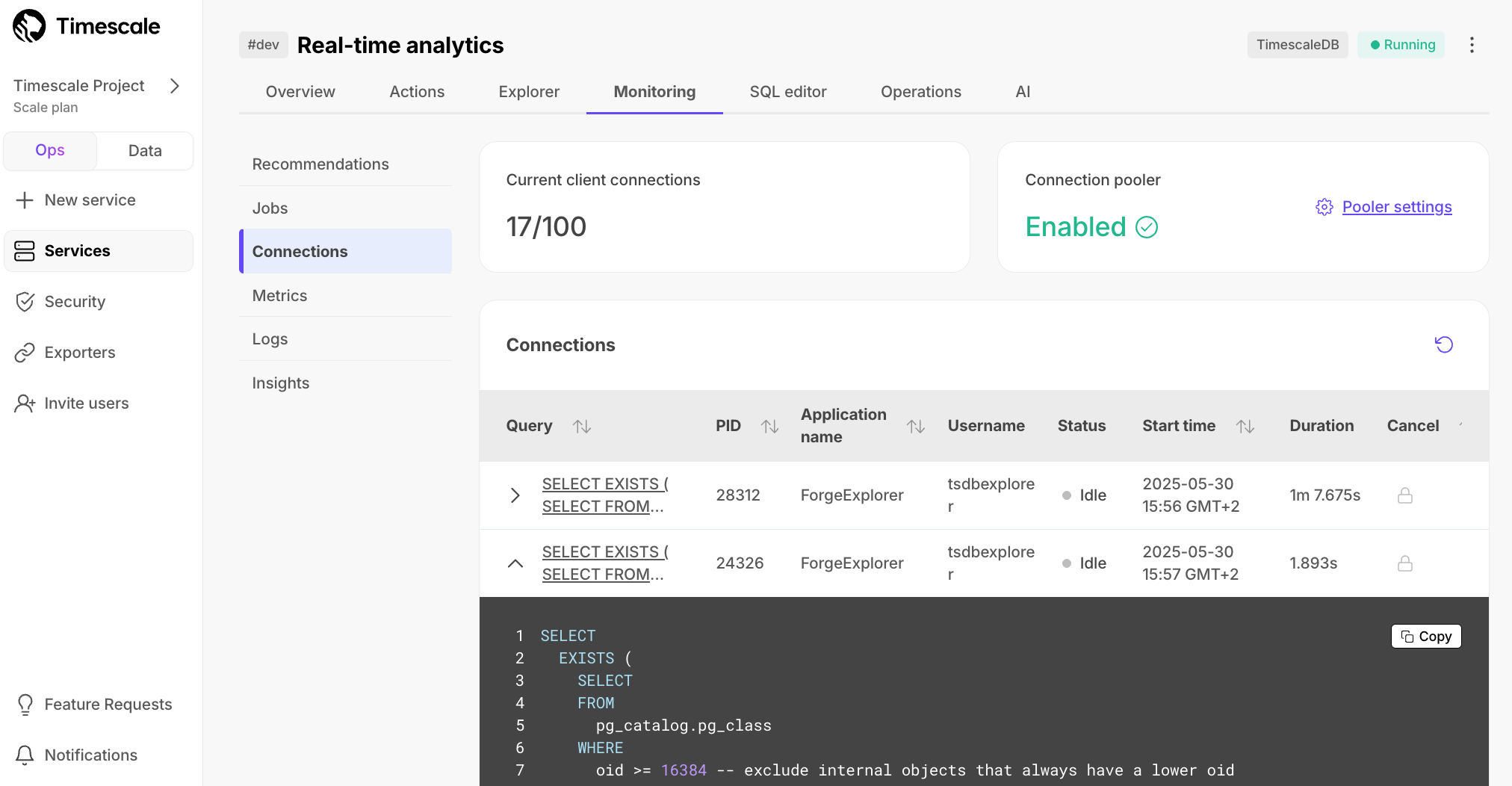
The information in Connections enables you to debug misconfigured applications, or
cancel problematic queries to free up other connections to your database.
TimescaleDB v2.20 - query performance and faster data updates
All new services created on Timescale Cloud are created using TimescaleDB v2.20. Existing services will be automatically upgraded during their maintenance window.
Highlighted features in TimescaleDB v2.20 include:
- Efficiently handle data updates and upserts (including backfills, that are now up to 10x faster).
- Up to 6x faster point queries on high-cardinality columns using new bloom filters.
- Up to 2500x faster DISTINCT operations with SkipScan, perfect for quickly getting a unique list or the latest reading from any device, event, or transaction.
- 8x more efficient Boolean column storage with vectorized processing, resulting in 30-45% faster queries.
- Enhanced developer flexibility with continuous aggregates now supporting window and mutable functions, plus customizable refresh orders.
Postgres 13 and 14 deprecated on Tiger Cloud
TimescaleDB version 2.20 is not compatible with Postgres versions v14 and below. TimescaleDB 2.19.3 is the last bug-fix release for Postgres 14. Future fixes are for Postgres 15+ only. To continue receiving critical fixes and security patches, and to take advantage of the latest TimescaleDB features, you must upgrade to Postgres 15 or newer. This deprecation affects all Tiger Cloud services currently running Postgres 13 or Postgres 14.
The timeline for the Postgres 13 and 14 deprecation is as follows:
- Deprecation notice period begins: starting in early June 2025, you will receive email communication.
- Customer self-service upgrade window: June 2025 through September 14, 2025. We strongly encourage you to manually upgrade Postgres during this period.
- Automatic upgrade deadline: your service will be automatically upgraded from September 15, 2025.
Enhancements to livesync for Postgres
You now can:
- Edit a running livesync to add and drop tables from an existing configuration:
- For existing tables, Timescale Console stops the livesync while keeping the target table intact.
- Newly added tables sync their existing data and transition into the Change Data Capture (CDC) state.
- Create multiple livesync instances for Postgres per service. This is an upgrade from our initial launch which limited users to one LiveSync per service.
This enables you to sync data from multiple Postgres source databases into a single Timescale Cloud service.
- No more hassle looking up schema and table names for livesync configuration from the source. Starting today, all schema and table names are available in a dropdown menu for seamless source table selection.
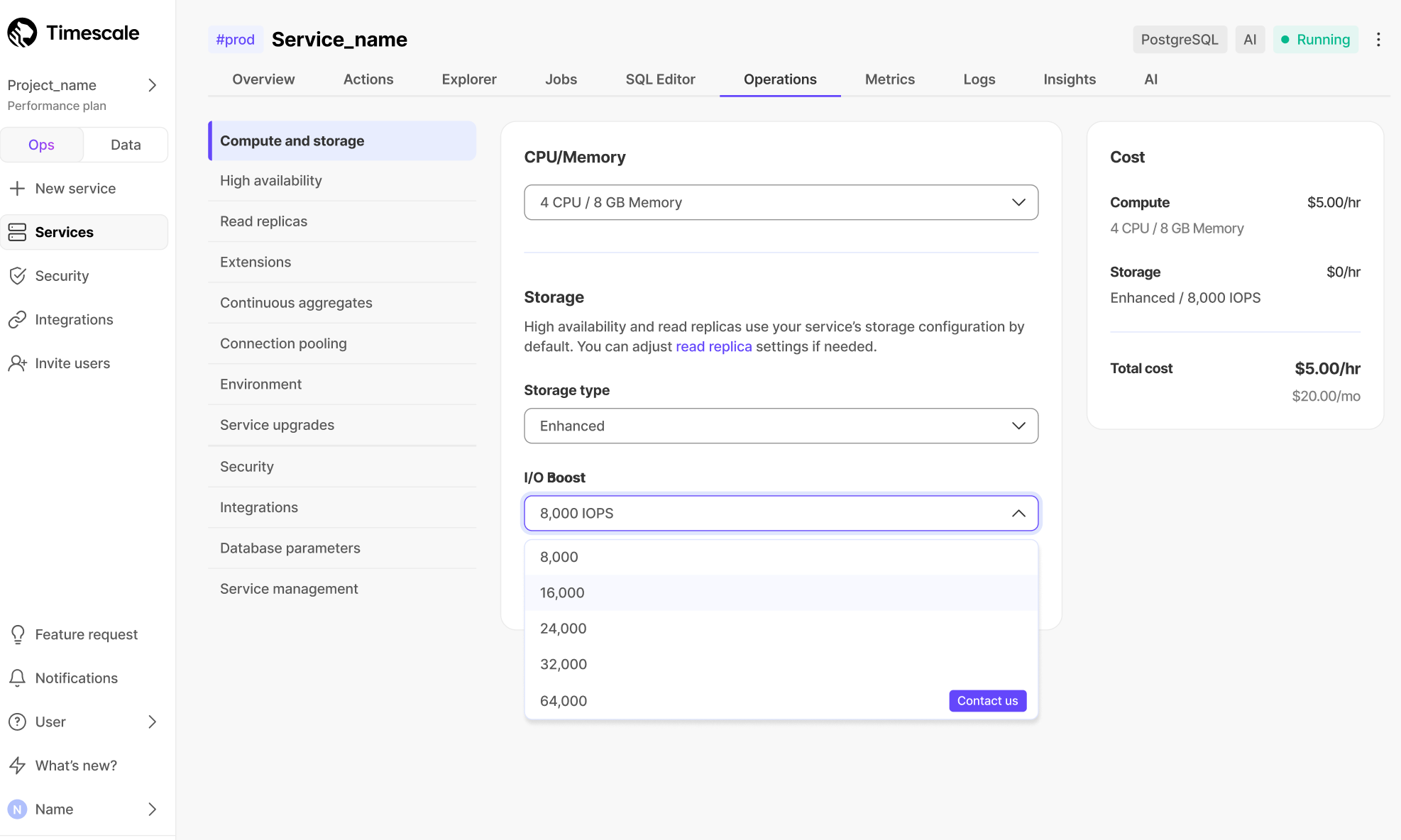
➕ More storage types and IOPS
May 22, 2025
🚀 Enhanced storage: scale to 64 TB and 32,000 IOPS
We're excited to introduce enhanced storage, a new storage type in Timescale Cloud that significantly boosts both capacity and performance. Designed for customers with mission-critical workloads.
With enhanced storage, Timescale Cloud now supports:
- Up to 64 TB of storage per Timescale Cloud service (4x increase from the previous limit)
- Up to 32,000 IOPS, enabling high-throughput ingest and low-latency queries
Powered by AWS io2 volumes, enhanced storage gives your workloads the headroom they need—whether you're building financial data pipelines, developing IoT platforms, or processing billions of rows of telemetry. No more worrying about storage ceilings or IOPS bottlenecks.
Enable enhanced storage in Timescale Console under Operations → Compute & Storage. Enhanced storage is currently available on the Enterprise pricing plan only. Learn more here.
↔️ New export and import options
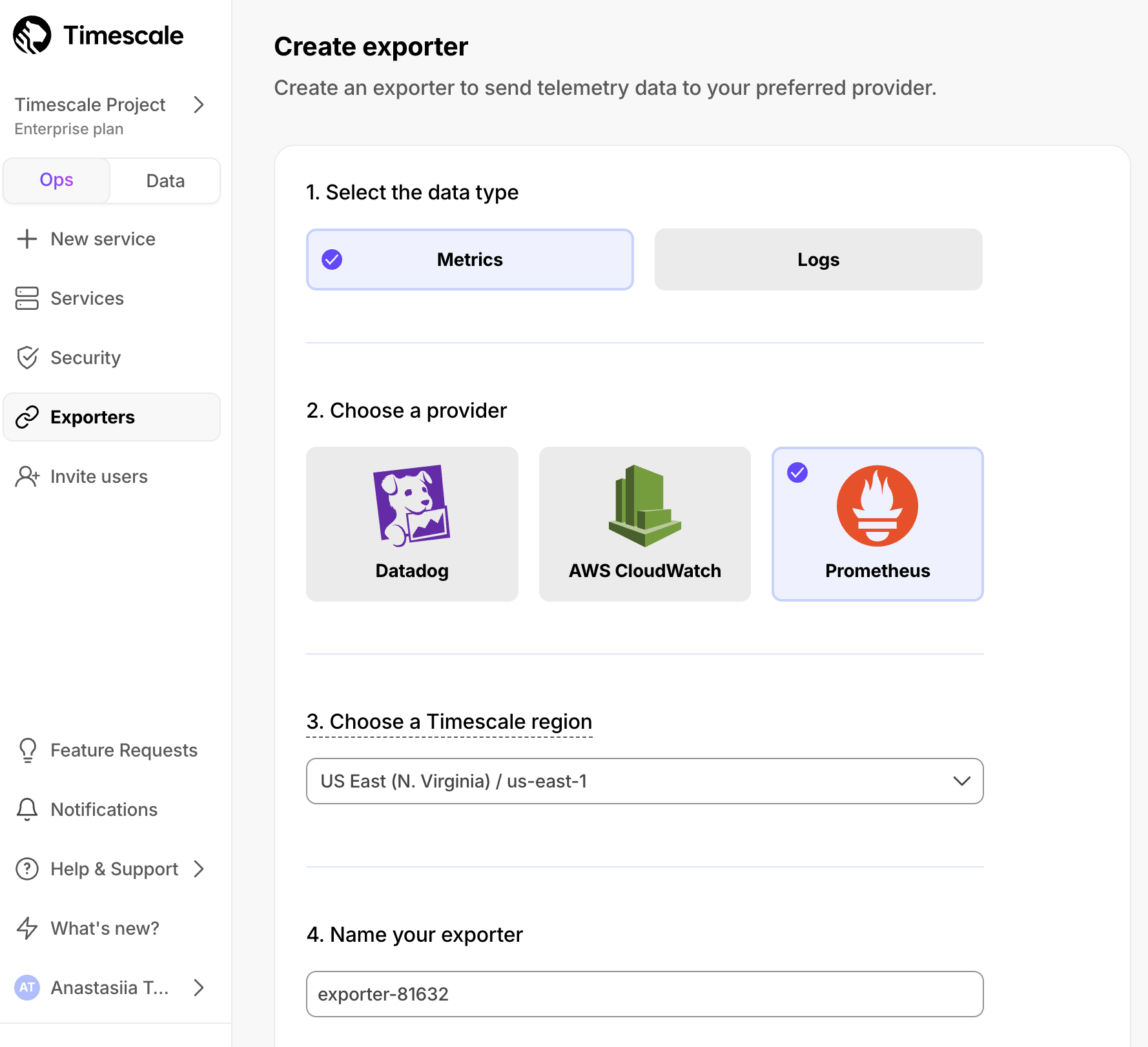
May 15, 2025
🔥 Ship TimescaleDB metrics to Prometheus
We’re excited to release the Prometheus Exporter for Timescale Cloud, making it easy to ship TimescaleDB metrics to your Prometheus instance. With the Prometheus Exporter, you can:
- Export TimescaleDB metrics like CPU, memory, and storage
- Visualize usage trends with your own Grafana dashboards
- Set alerts for high CPU load, low memory, or storage nearing capacity
To get started, create a Prometheus Exporter in the Timescale Console, attach it to your service, and configure Prometheus to scrape from the exposed URL. Metrics are secured with basic auth. Available on Scale and Enterprise plans. Learn more here.
📥 Import text files into Postgres tables
Our import options in Timescale Console have expanded to include local text files. You can add the content of multiple text files (one file per row) into a Postgres table for use with Vectorizers while creating embeddings for evaluation and development. This new option is located in Service > Actions > Import Data.
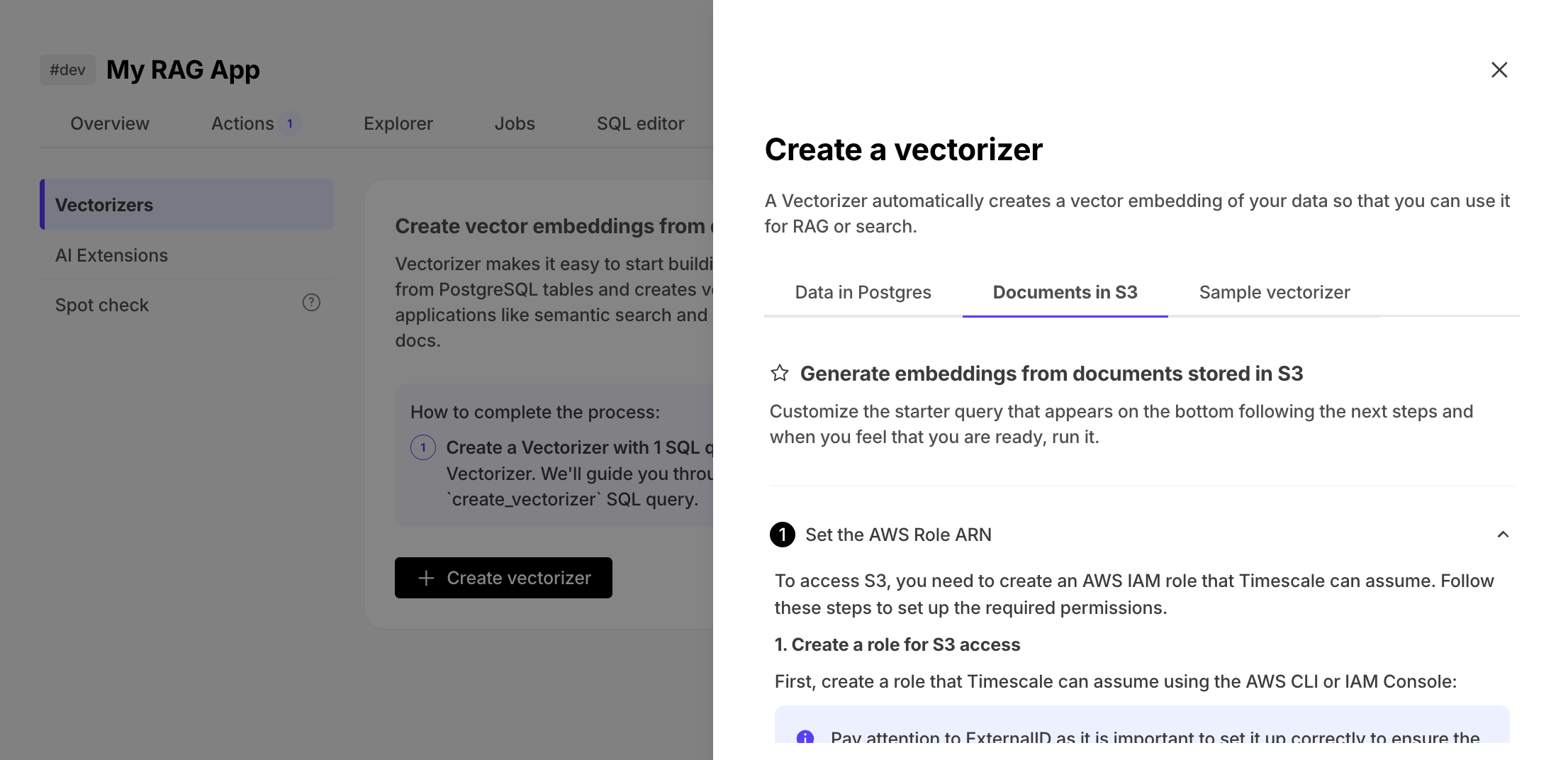
🤖 Automatic document embeddings from S3 and a sample dataset for AI testing
May 09, 2025
Automatic document embeddings from S3
pgai vectorizer now supports automatic document vectorization. This makes it dramatically easier to build RAG and semantic search applications on top of unstructured data stored in Amazon S3. With just a SQL command, developers can create, update, and synchronize vector embeddings from a wide range of document formats—including PDFs, DOCX, XLSX, HTML, and more—without building or maintaining complex ETL pipelines.
Instead of juggling multiple systems and syncing metadata, vectorizer handles the entire process: downloading documents from S3, parsing them, chunking text, and generating vector embeddings stored right in Postgres using pgvector. As documents change, embeddings stay up-to-date automatically—keeping your Postgres database the single source of truth for both structured and semantic data.
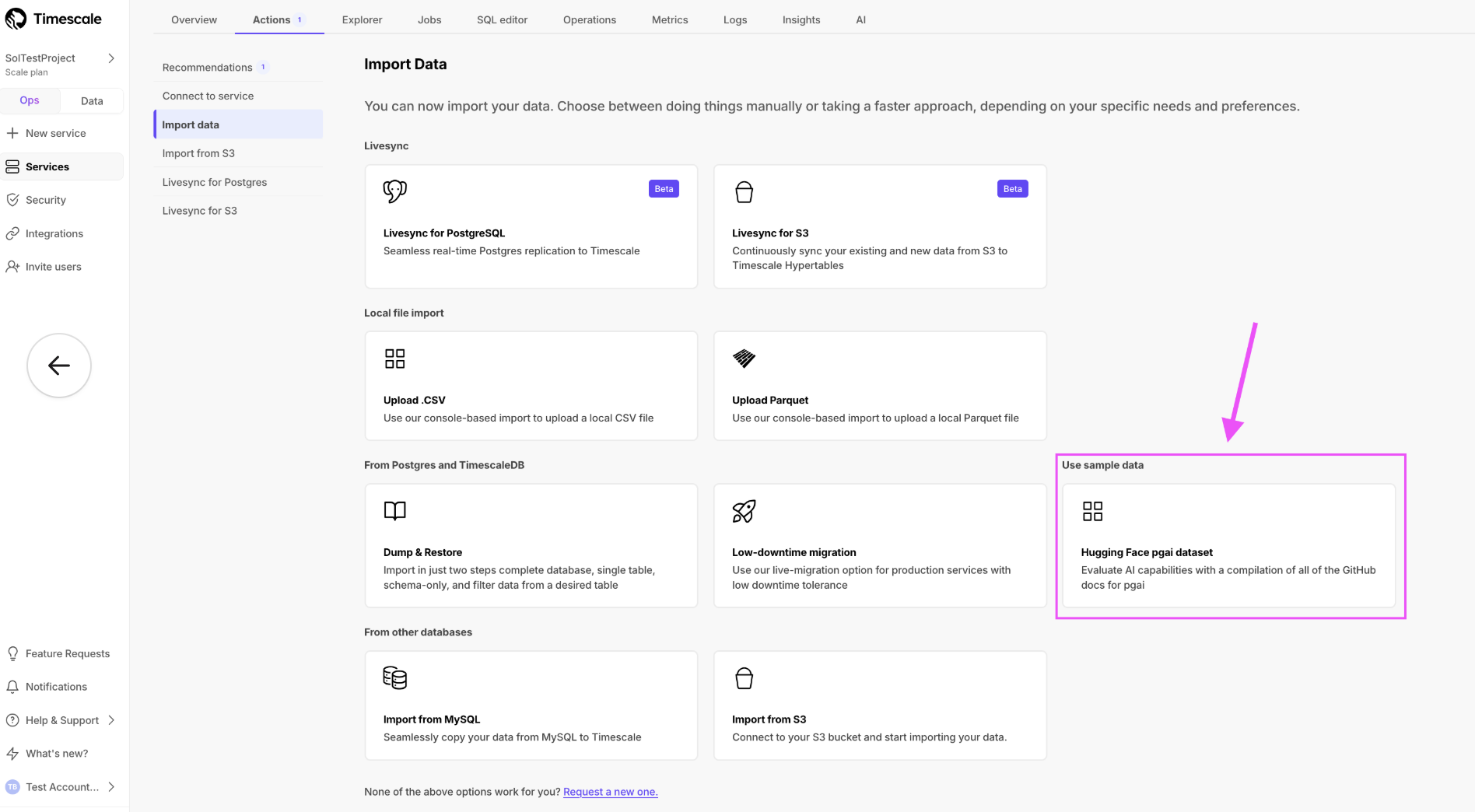
Sample dataset for AI testing
You can now import a dataset directly from Hugging Face using Timescale Console. This dataset is ideal for testing vectorizers, you find it in the Import Data page under the Service > Actions tab.
🔁 Livesync for S3 and passwordless connections for data mode
April 25, 2025
Livesync for S3 (beta)
Livesync for S3 is our second livesync offering in Timescale Console, following livesync for Postgres. This feature helps users sync data in their S3 buckets to a Timescale Cloud service, and simplifies data importing. Livesync handles both existing and new data in real time, automatically syncing everything into a Timescale Cloud service. Users can integrate Timescale Cloud alongside S3, where S3 stores data in raw form as the source for multiple destinations.

With livesync, users can connect Timescale Cloud with S3 in minutes, rather than spending days setting up and maintaining an ingestion layer.
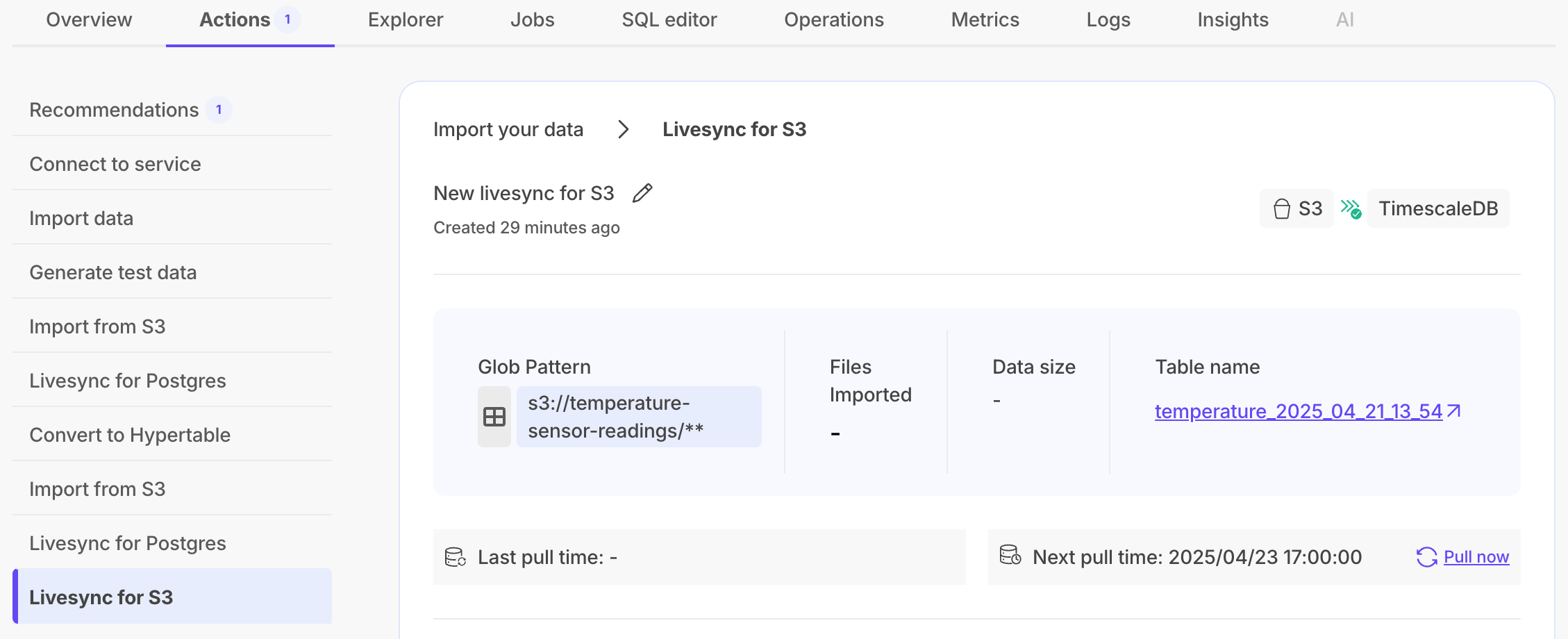
UX improvements to livesync for Postgres
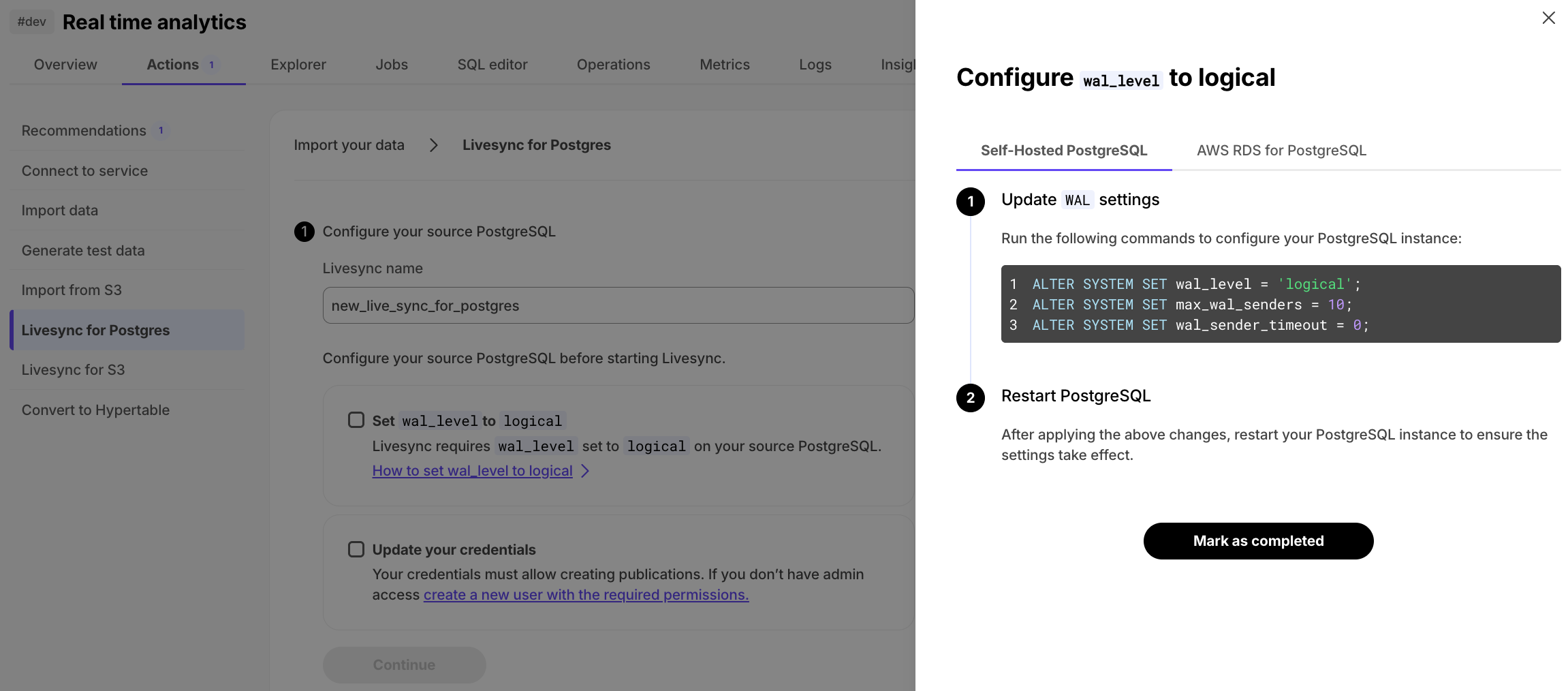
In livesync for Postgres, getting started
requires setting the WAL_LEVEL to logical, and granting specific permissions to start a publication
on the source database. To simplify this setup process, we have added a detailed two-step checklist with comprehensive
configuration instructions to Timescale Console.
Passwordless data mode connections
We’ve made connecting to your Timescale Cloud services from data mode in Timescale Console even easier! All new services created in Timescale Cloud are now automatically accessible from data mode without requiring you to enter your service credentials. Just open data mode, select your service, and start querying.
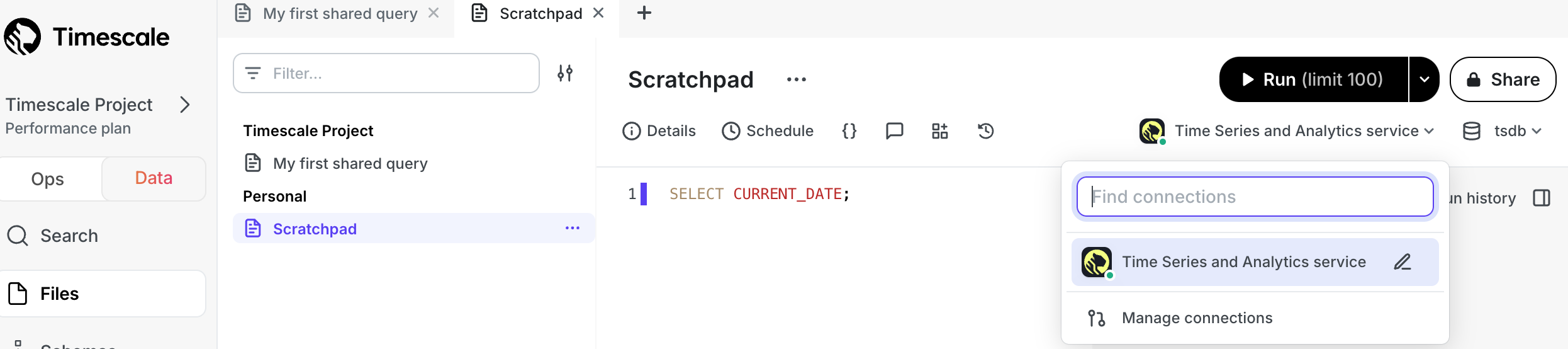
We will be expanding this functionality to existing services in the coming weeks (including services using VPC peering), so stay tuned.
☑️ Embeddings spot checks, TimescaleDB v2.19.3, and new models in SQL Assistant
April 18, 2025
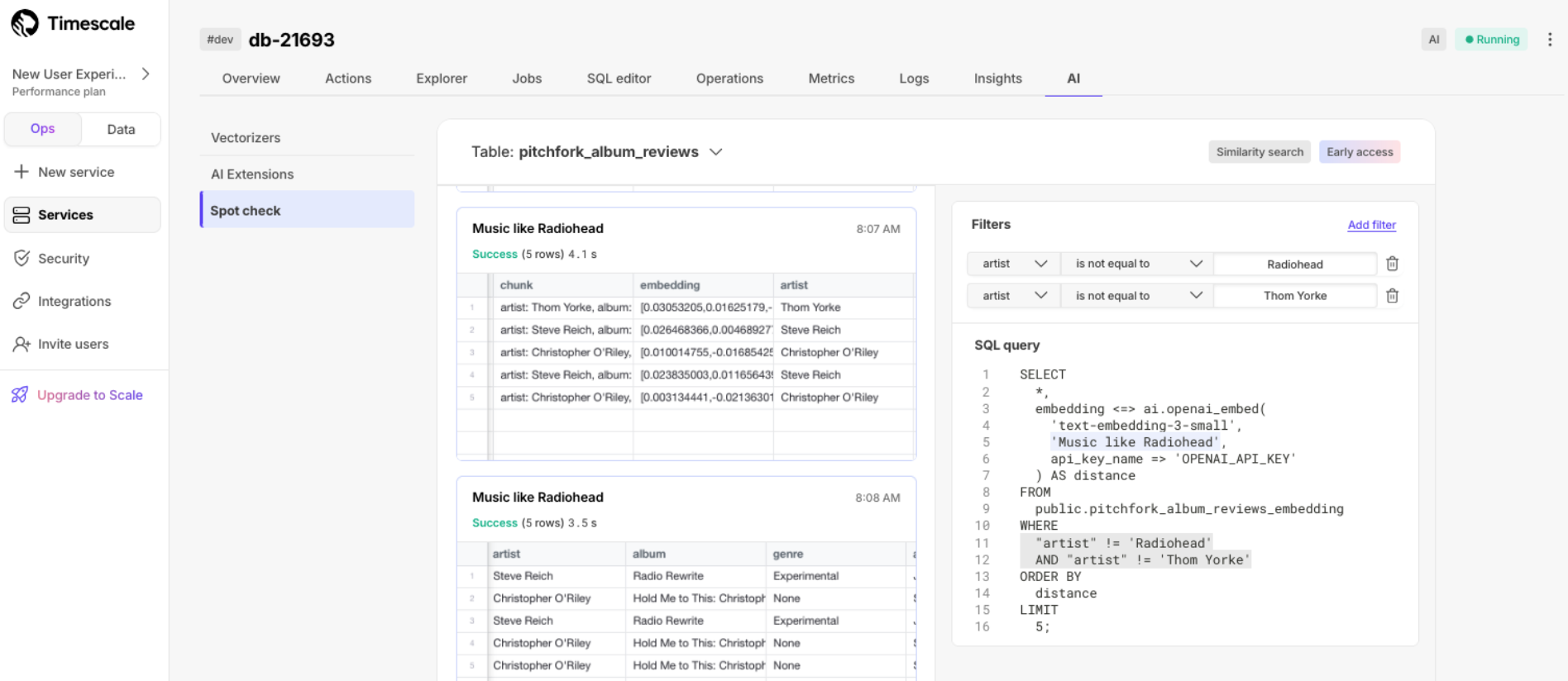
Embeddings spot checks
In Timescale Cloud, you can now quickly check the quality of the embeddings from the vectorizers' outputs. Construct a similarity search query with additional filters on source metadata using a simple UI. Run the query right away, or copy it to the SQL editor or data mode and further customize it to your needs. Run the check in Timescale Console > Services > AI:
TimescaleDB v2.19.3
New services created in Timescale Cloud now use TimescaleDB v2.19.3. Existing services are in the process of being automatically upgraded to this version.
This release adds a number of bug fixes including:
- Fix segfault when running a query against columnstore chunks that group by multiple columns, including UUID segmentby columns.
- Fix hypercore table access method segfault on DELETE operations using a segmentby column.
New OpenAI, Llama, and Gemini models in SQL Assistant
The data mode's SQL Assistant now includes support for the latest models from OpenAI and Llama: GPT-4.1 (including mini and nano) and Llama 4 (Scout and Maverick). Additionally, we've added support for Gemini models, in particular Gemini 2.0 Nano and 2.5 Pro (experimental and preview). With the new additions, SQL Assistant supports more than 20 language models so you can select the one best suited to your needs.
🪵 TimescaleDB v2.19, new service overview page, and log improvements
April 11, 2025
TimescaleDB v2.19—query performance and concurrency improvements
Starting this week, all new services created on Timescale Cloud use TimescaleDB v2.19. Existing services will be upgraded gradually during their maintenance window.
Highlighted features in TimescaleDB v2.19 include:
- Improved concurrency of
INSERT,UPDATE, andDELETEoperations on the columnstore by no longer blocking DML statements during the recompression of a chunk. - Improved system performance during continuous aggregate refreshes by breaking them into smaller batches. This reduces systems pressure and minimizes the risk of spilling to disk.
- Faster and more up-to-date results for queries against continuous aggregates by materializing the most recent data first, as opposed to old data first in prior versions.
- Faster analytical queries with SIMD vectorization of aggregations over text columns and
GROUP BYover multiple columns. - Enable chunk size optimization for better query performance in the columnstore by merging them with
merge_chunk.
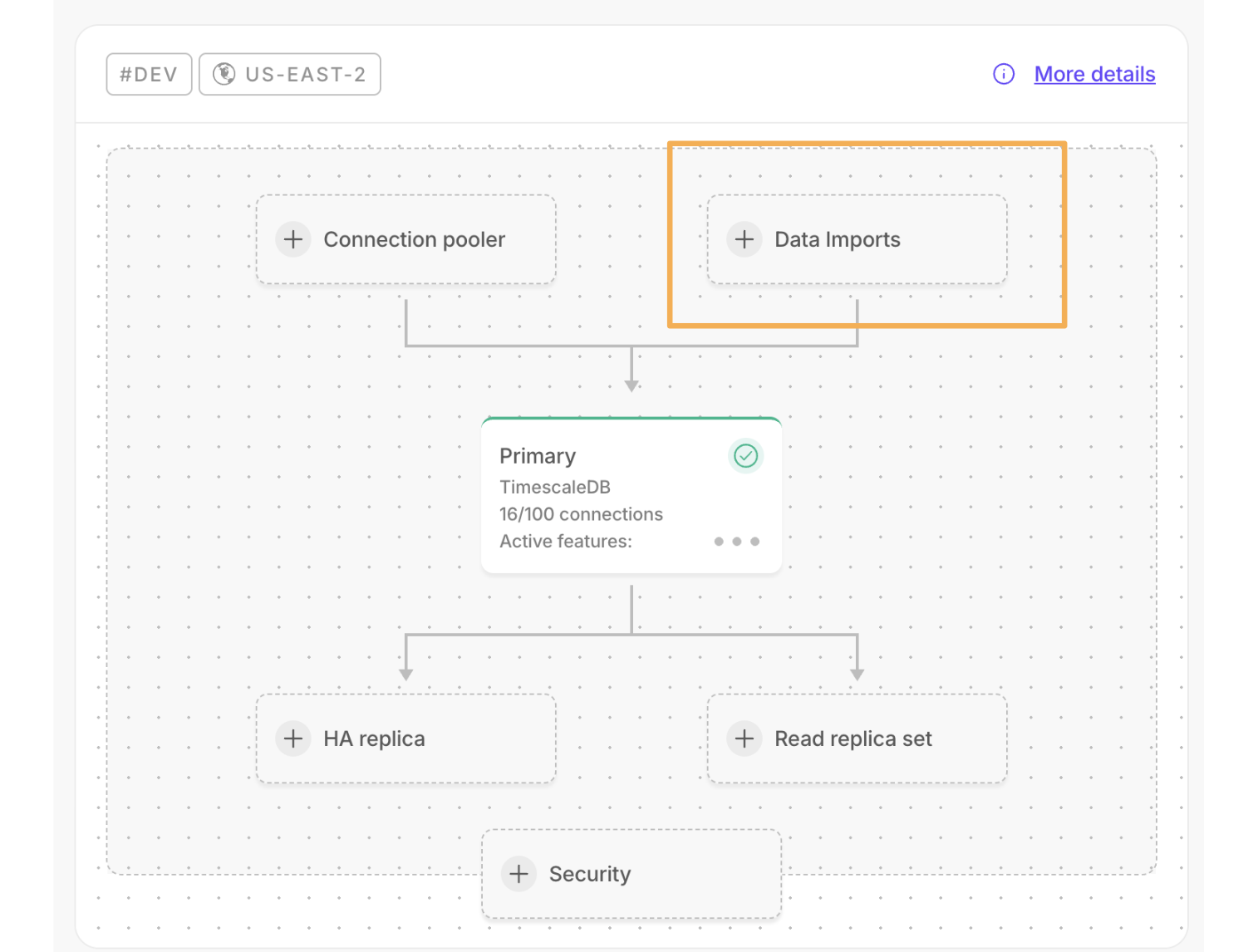
New service overview page
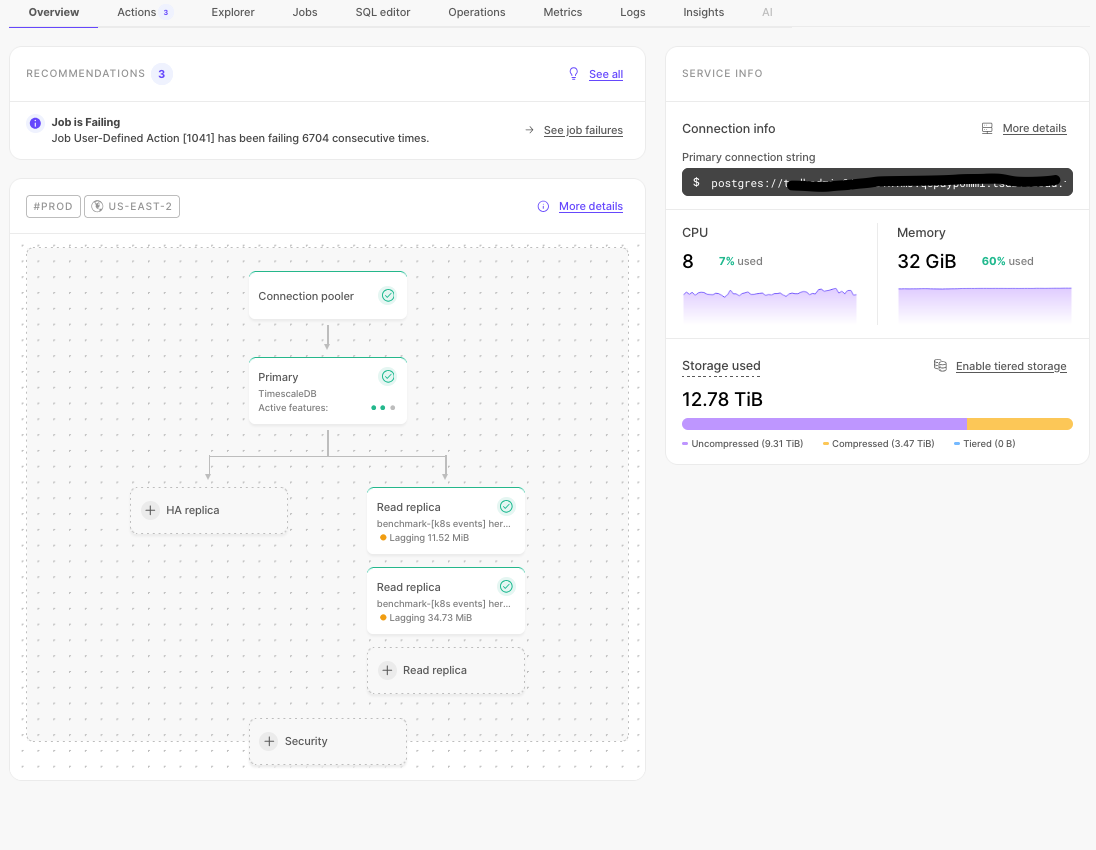
The service overview page in Timescale Console has been overhauled to make it simpler and easier to use. Navigate to the Overview tab for any of your services and you will find an architecture diagram and general information pertaining to it. You may also see recommendations at the top, for how to optimize your service.
To leave the product team your feedback, open Help & Support on the left and select Send feedback to the product team.
Finding logs just got easier! We've added a date, time, and timezone picker, so you can jump straight to the exact moment you're interested in—no more endless scrolling.

📒Faster vector search and improved job information
April 4, 2025
pgvectorscale 0.7.0: faster filtered filtered vector search with filtered indexes
This pgvectorscale release adds label-based filtered vector search to the StreamingDiskANN index. This enables you to return more precise and efficient results by combining vector similarity search with label filtering while still uitilizing the ANN index. This is a common need for large-scale RAG and Agentic applications that rely on vector searches with metadata filters to return relevant results. Filtered indexes add even more capabilities for filtered search at scale, complementing the high accuracy streaming filtering already present in pgvectorscale. The implementation is inspired by Microsoft's Filtered DiskANN research. For more information, see the [pgvectorscale release notes][log-28032025-pgvectorscale-rn] and a [usage example][log-28032025-pgvectorscale-example].
Job errors and individual job pages
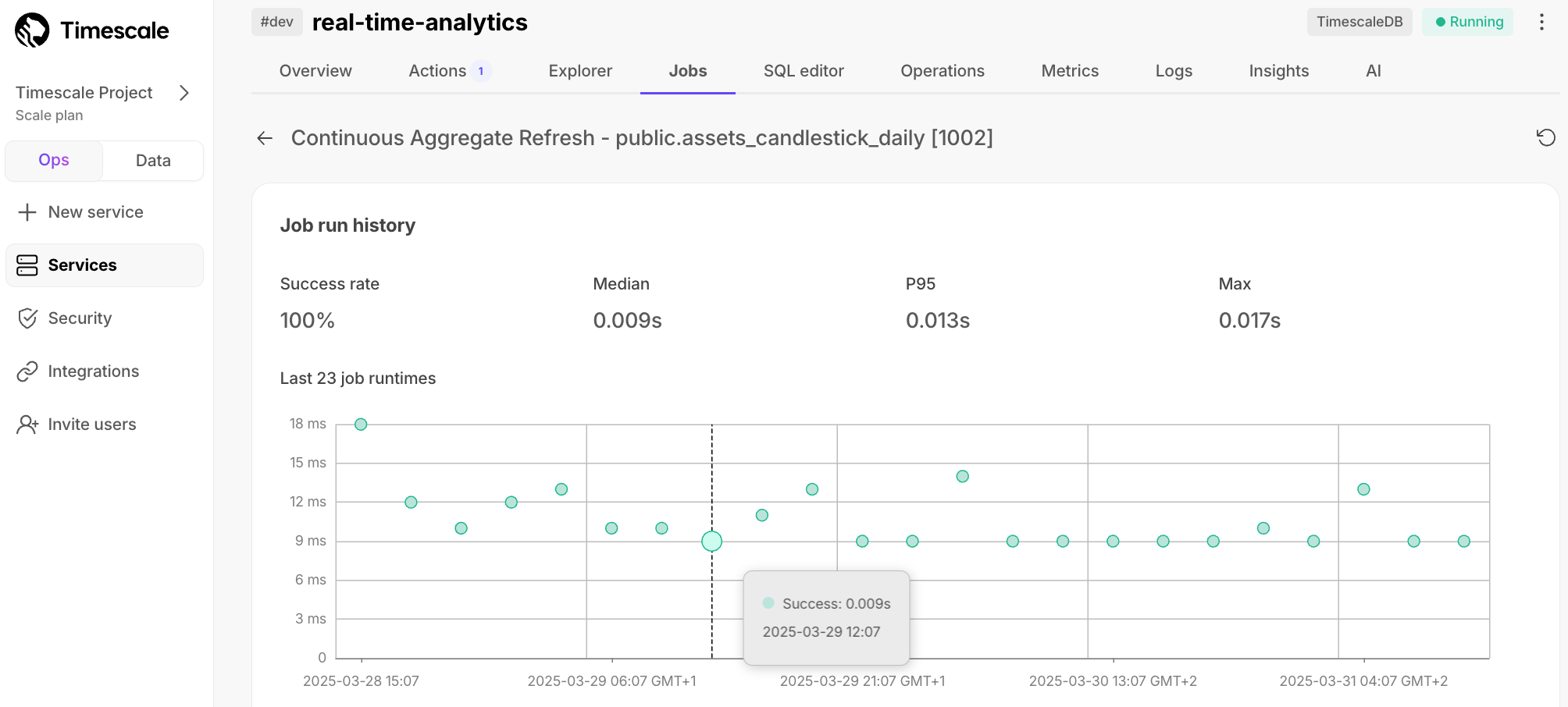
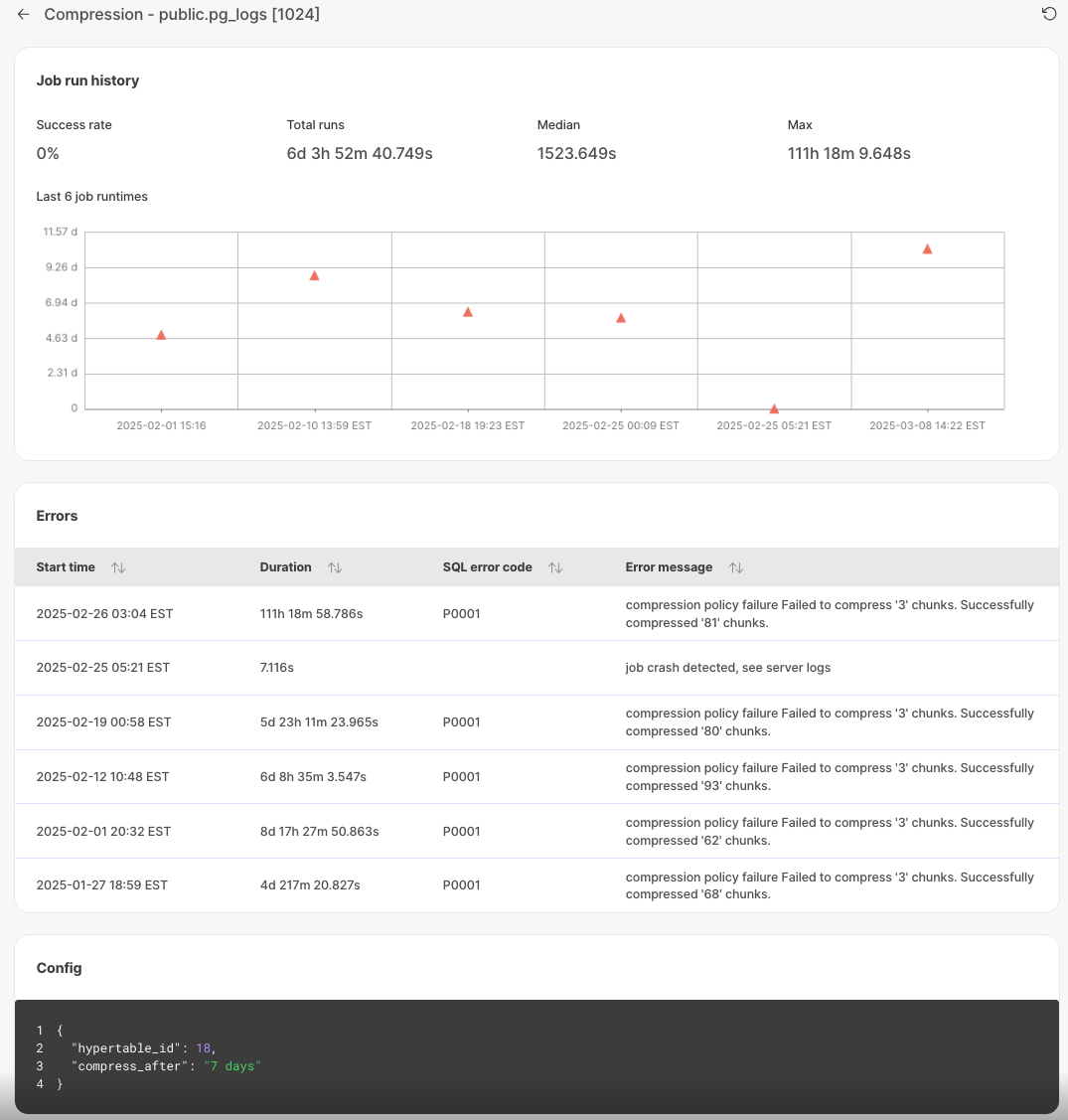
Each job now has an individual page in Timescale Console, and displays additional details about job errors. You use this information to debug failing jobs.
To see the job information page, in [Timescale Console][console], select the service to check, then click Jobs > job ID to investigate.
- Unsuccessful jobs with errors:
🤩 In-Console Livesync for Postgres
March 21, 2025
You can now set up an active data ingestion pipeline with livesync for Postgres in Timescale Console. This tool enables you to replicate your source database tables into Timescale's hypertables indefinitely. Yes, you heard that right—keep livesync running for as long as you need, ensuring that your existing source Postgres tables stay in sync with Timescale Cloud. Read more about setting up and using Livesync for Postgres.
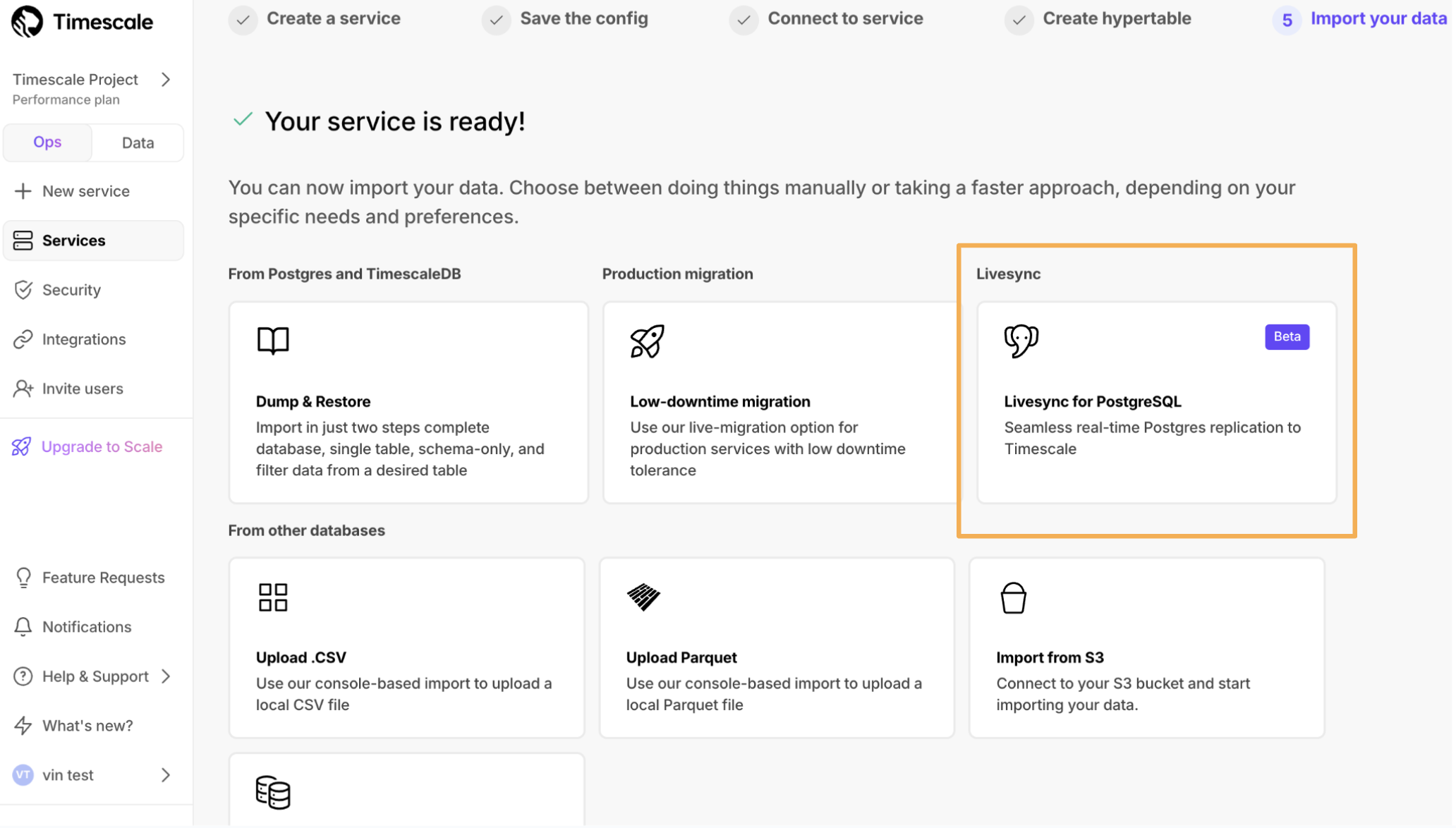
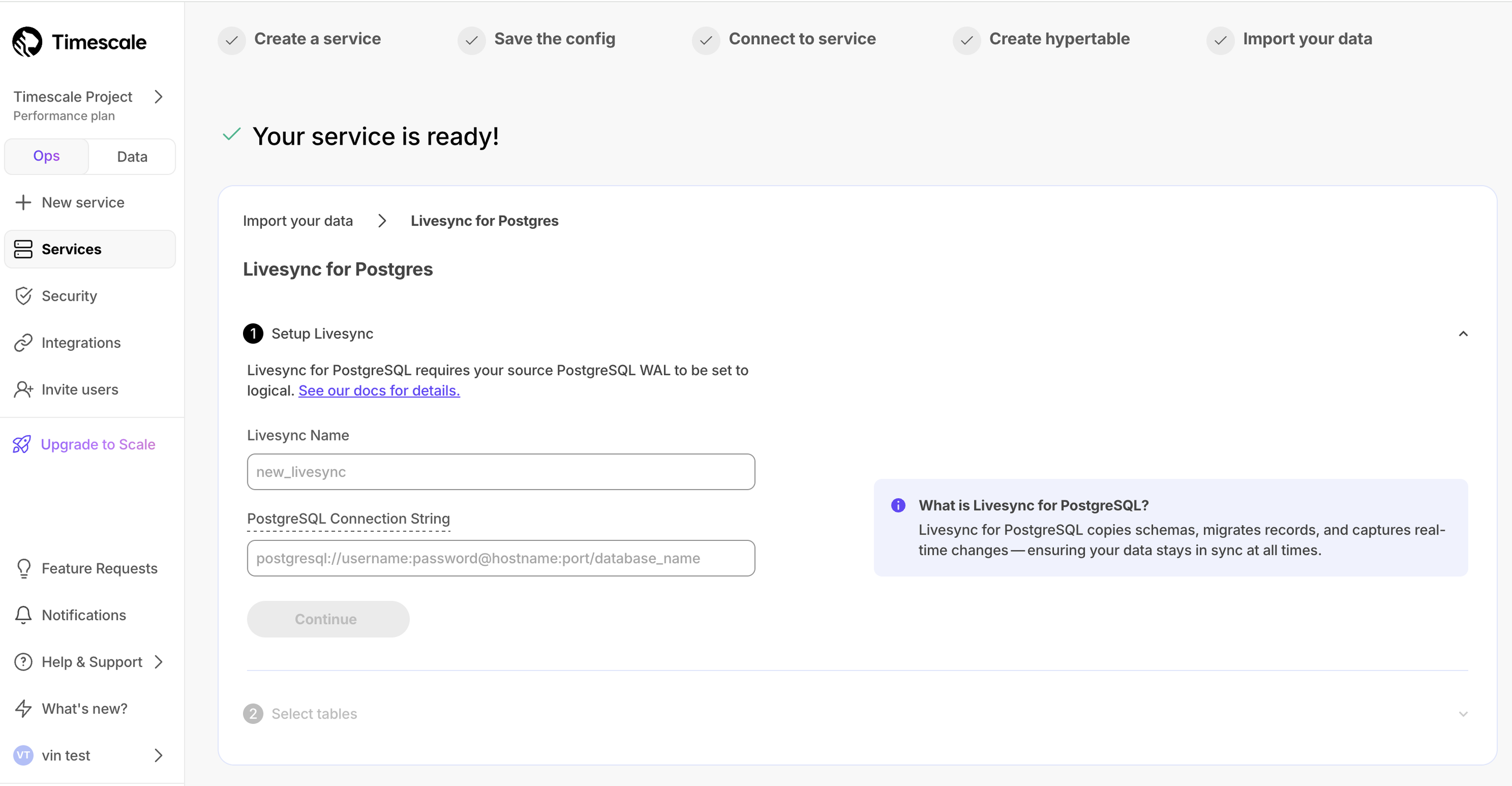
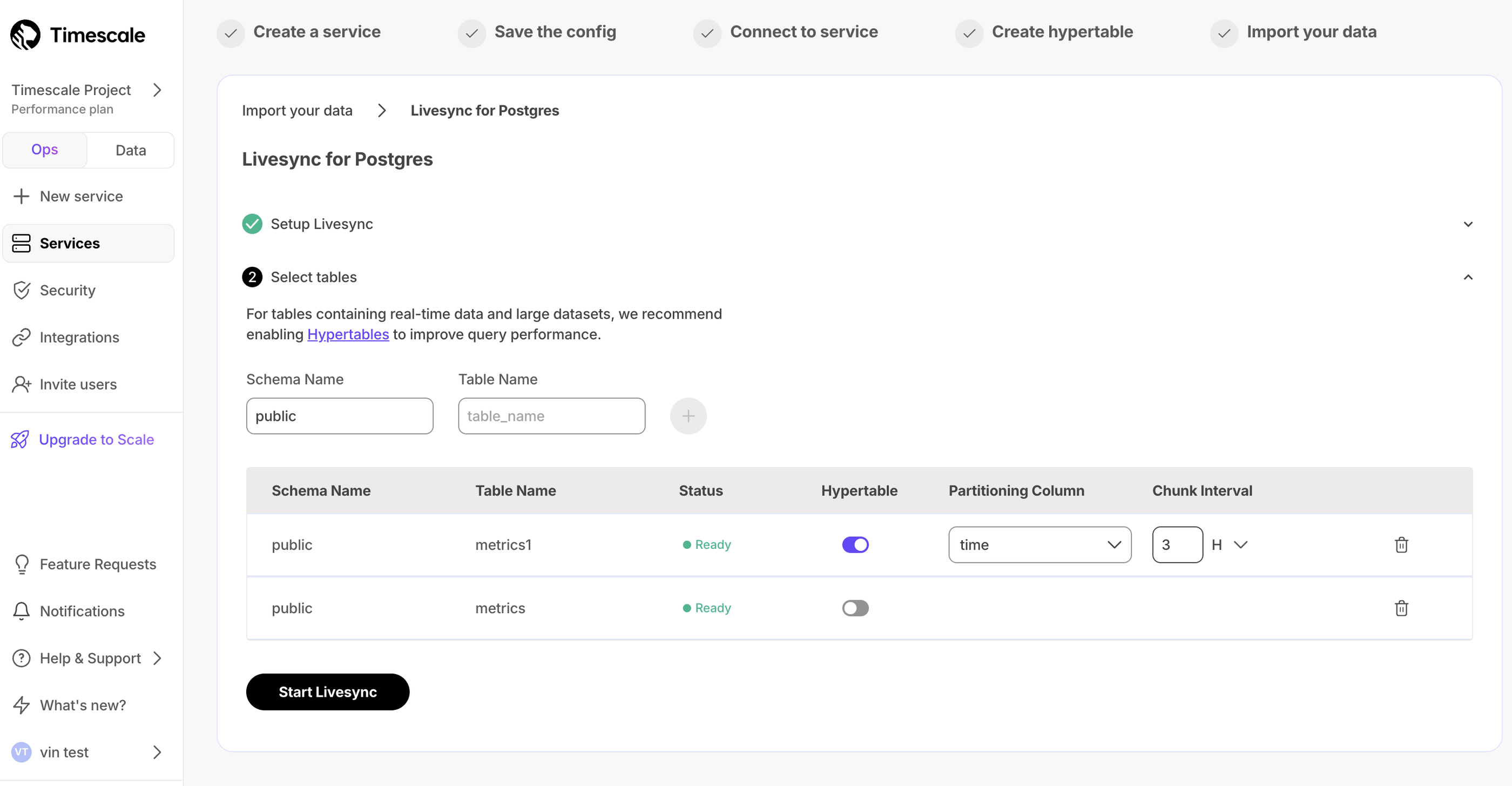
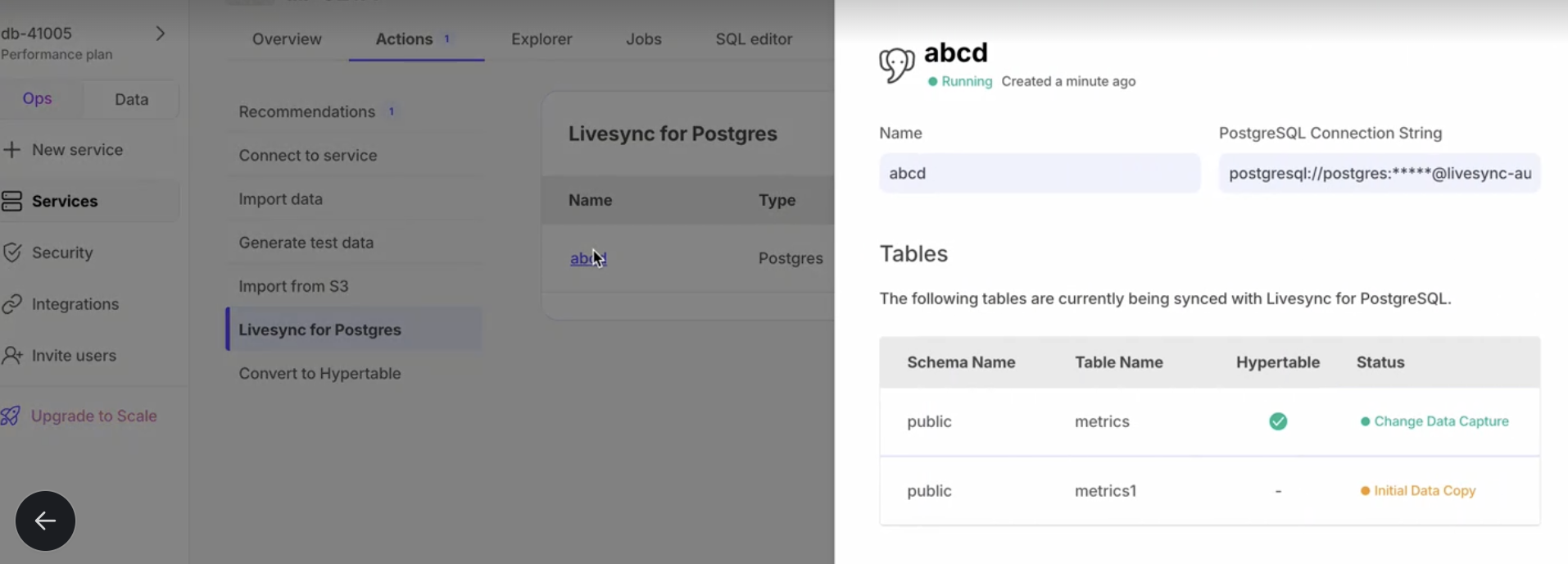
💾 16K dimensions on pgvectorscale plus new pgai Vectorizer support
March 14, 2025
pgvectorscale 0.6 — store up to 16K dimension embeddings
pgvectorscale 0.6.0 now supports storing vectors with up to 16,000 dimensions, removing the previous limitation of 2,000 from pgvector. This lets you use larger embedding models like OpenAI's text-embedding-3-large (3072 dim) with Postgres as your vector database. This release also includes key performance and capability enhancements, including NEON support for SIMD distance calculations on aarch64 processors, improved inner product distance metric implementation, and improved index statistics. See the release details here.
pgai Vectorizer supports models from AWS Bedrock, Azure AI, Google Vertex via LiteLLM
Access embedding models from popular cloud model hubs like AWS Bedrock, Azure AI Foundry, Google Vertex, as well as HuggingFace and Cohere as part of the LiteLLM integration with pgai Vectorizer. To use these models with pgai Vectorizer on Timescale Cloud, select Other when adding the API key in the credentials section of Timescale Console.
🤖 Agent Mode for PopSQL and more
March 7, 2025
Agent Mode for PopSQL
Introducing Agent Mode, a new feature in Timescale Console SQL Assistant. SQL Assistant lets you query your database using natural language. However, if you ran into errors, you have to approve the implementation of the Assistant's suggestions.
With Agent Mode on, SQL Assistant automatically adjusts and executes your query without intervention. It runs, diagnoses, and fixes any errors that it runs into until you get your desired results.
Below you can see SQL Assistant run into an error, identify the resolution, execute the fixed query, display results, and even change the title of the query:
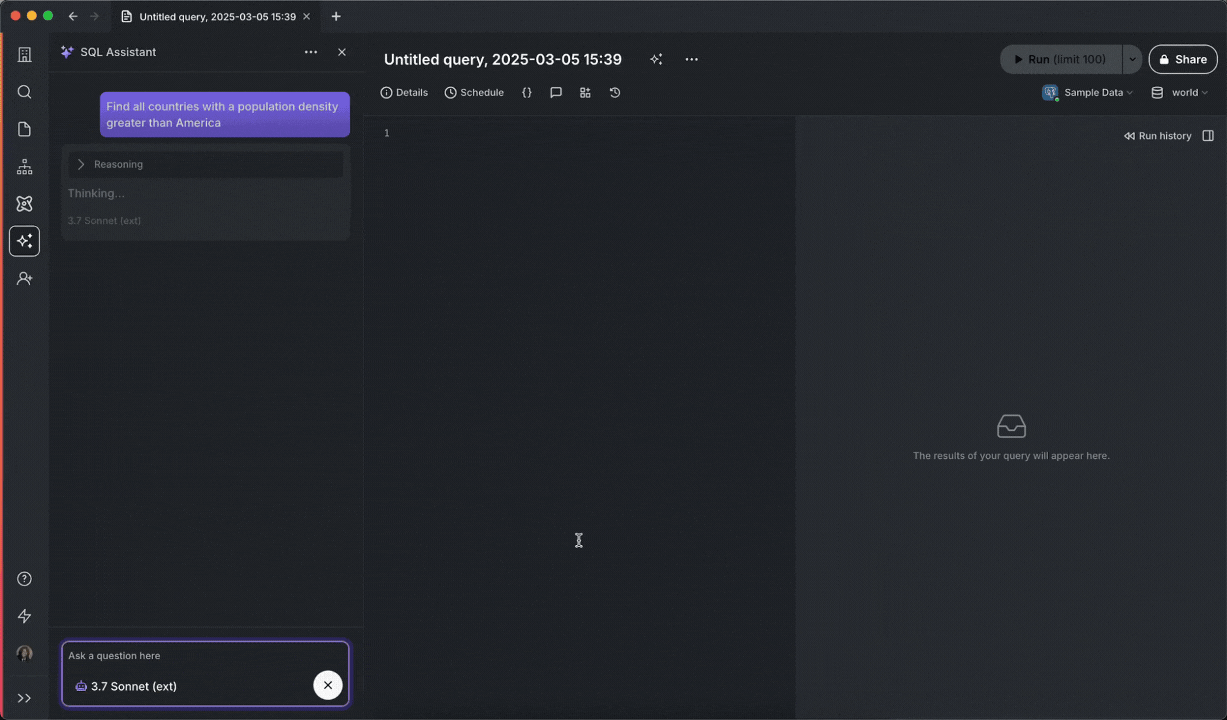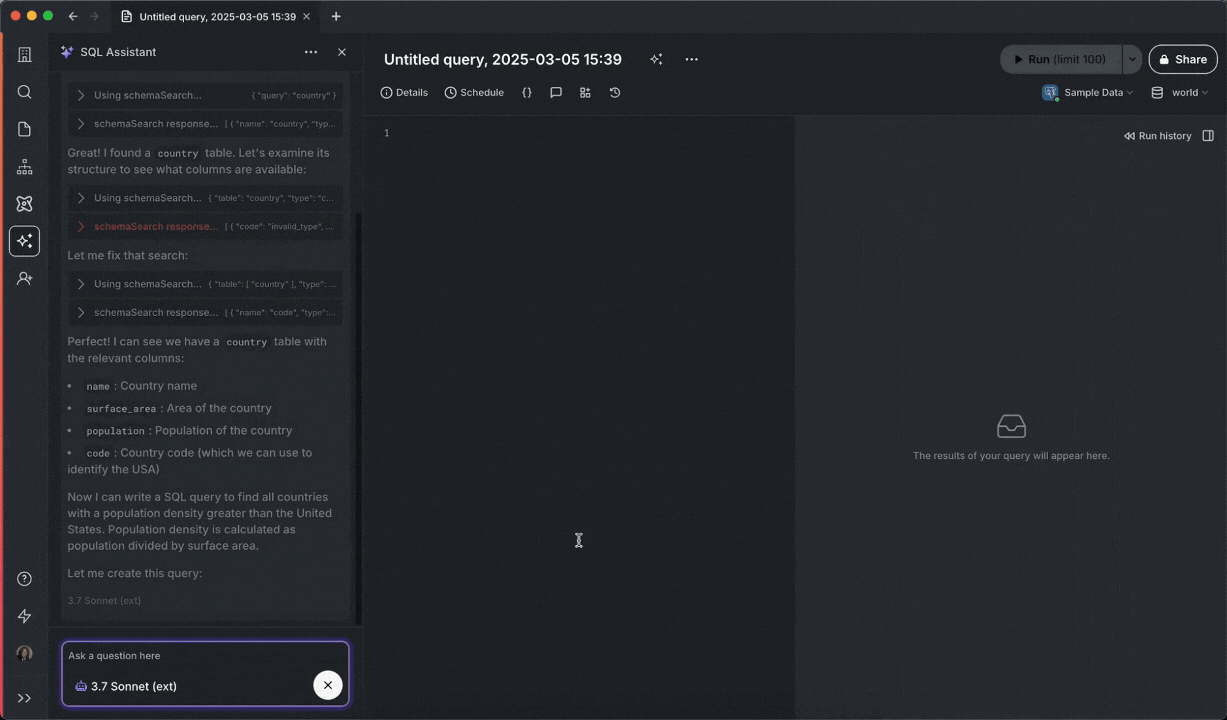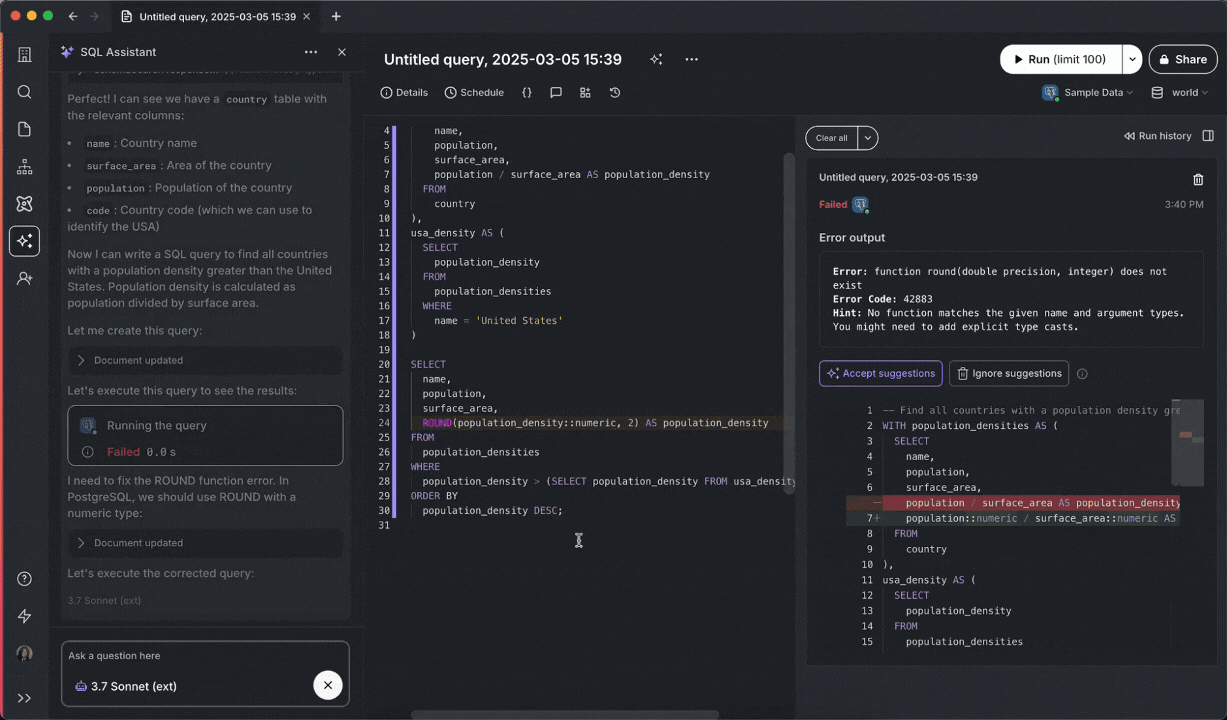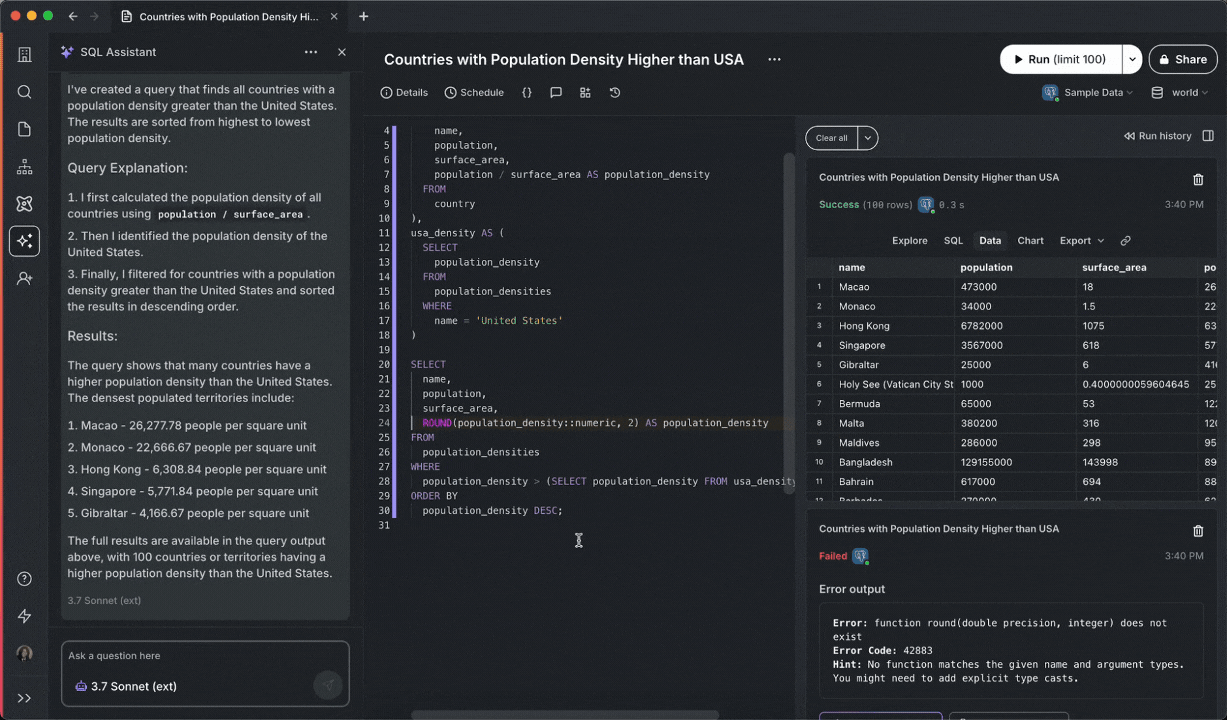
To use Agent Mode, make sure you have SQL Assistant enabled, then click on the model selector dropdown, and tick the Agent Mode checkbox.
Improved AWS Marketplace integration for a smoother experience
We've enhanced the AWS Marketplace workflow to make your experience even better! Now, everything is fully automated, ensuring a seamless process from setup to billing. If you're using the AWS Marketplace integration, you'll notice a smoother transition and clearer billing visibility—your Timescale Cloud subscription will be reflected directly in AWS Marketplace!
Timescale Console recommendations
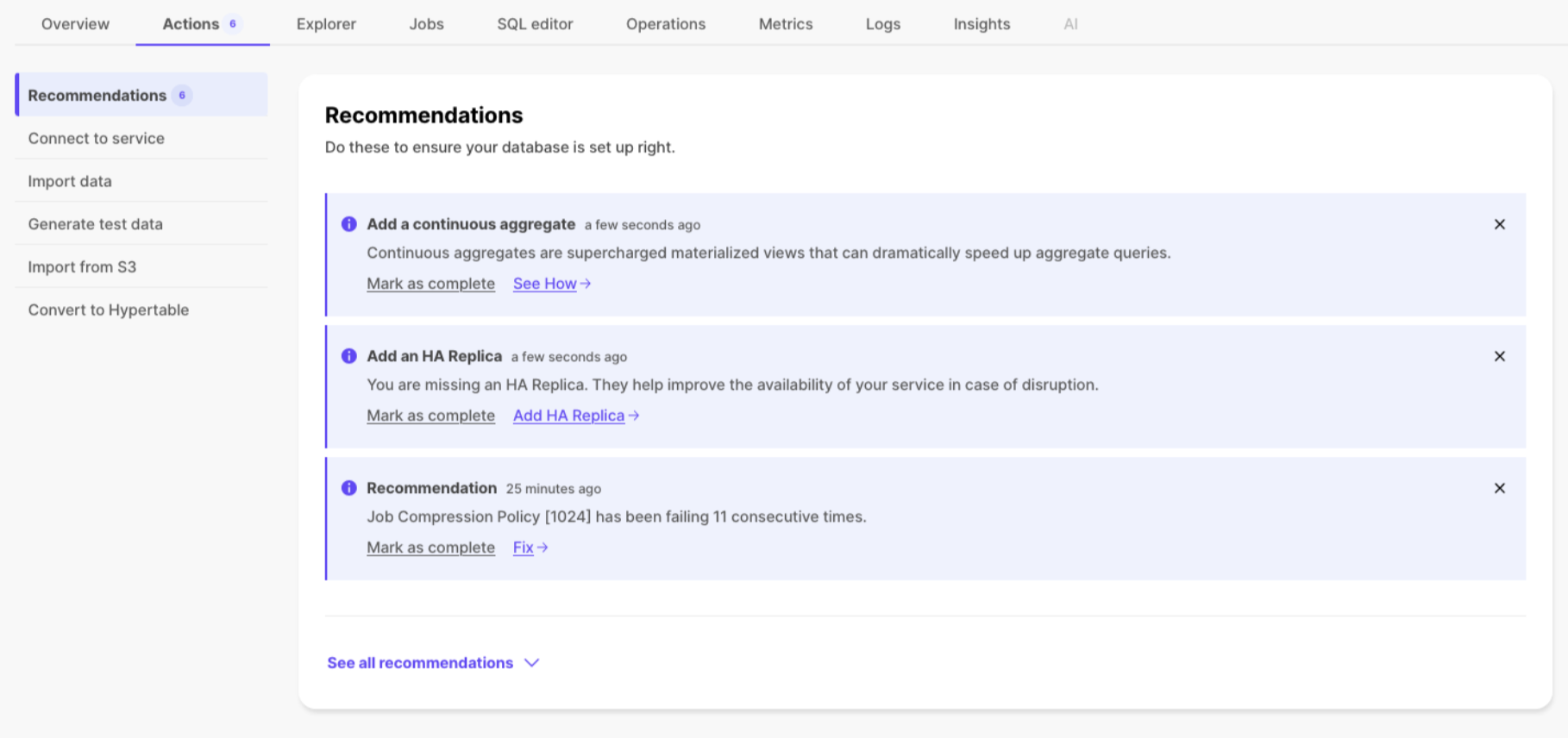
Sometimes it can be hard to know if you are getting the best use out of your service. To help with this, Timescale Cloud now provides recommendations based on your service's context, assisting with onboarding or notifying if there is a configuration concern with your service, such as consistently failing jobs.
To start, recommendations are focused primarily on onboarding or service health, though we will regularly add new ones. You can see if you have any existing recommendations for your service by going to the Actions tab in Timescale Console.
🛣️ Configuration Options for Secure Connections and More
February 28, 2025
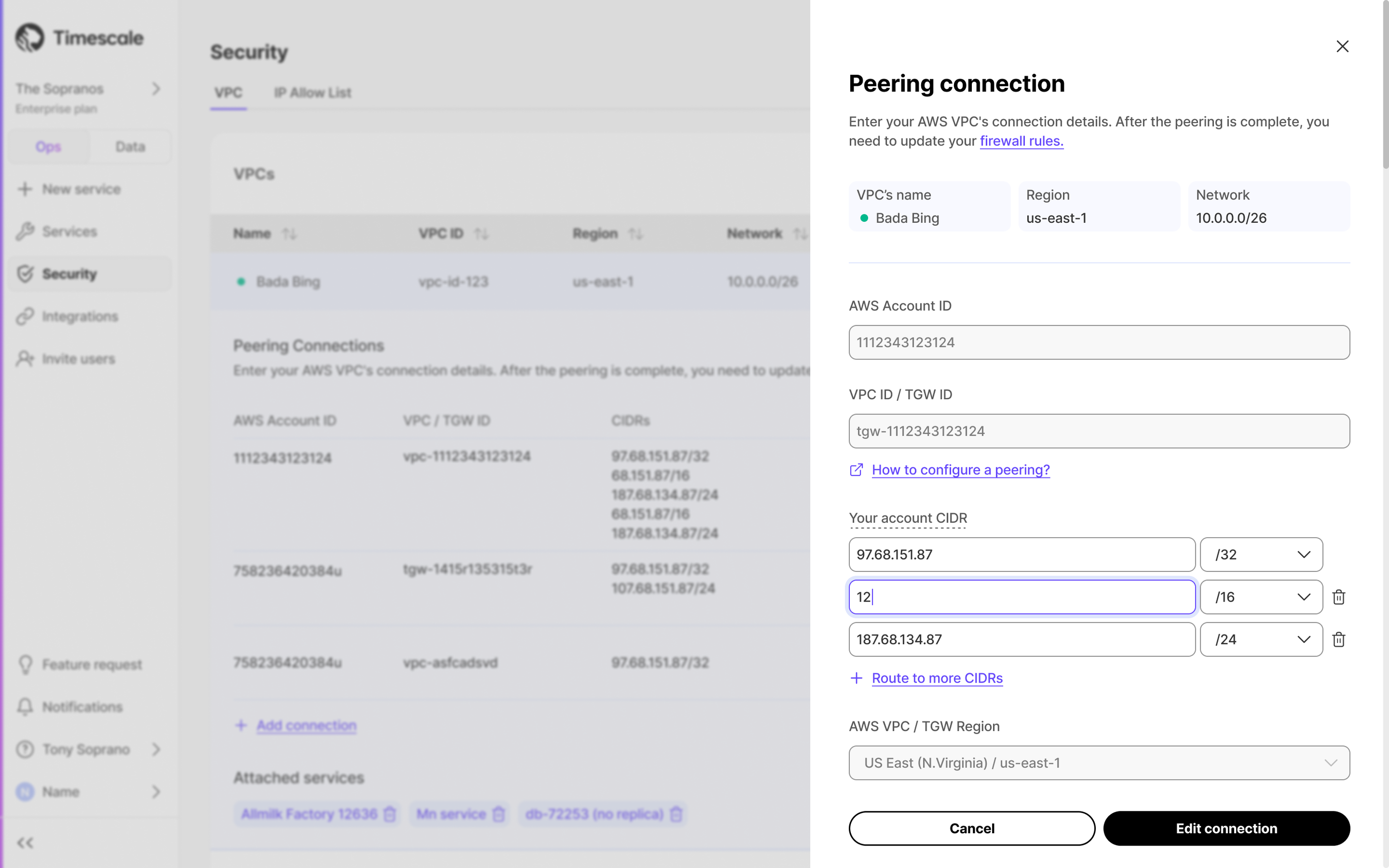
Edit VPC and AWS Transit Gateway CIDRs
You can now modify the CIDRs blocks for your VPC or Transit Gateway directly from Timescale Console, giving you greater control over network access and security. This update makes it easier to adjust your private networking setup without needing to recreate your VPC or contact support.
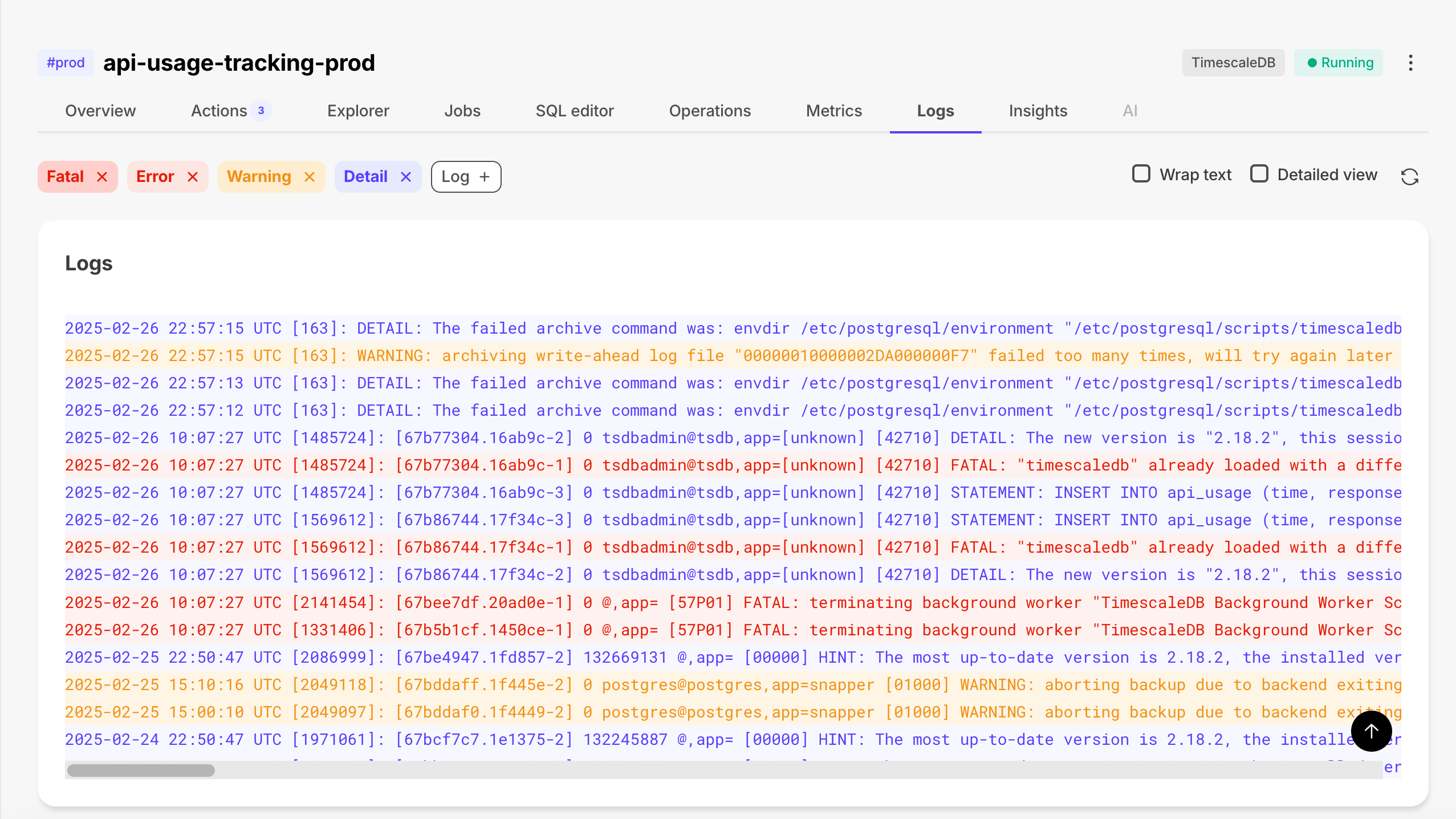
Improved log filtering
We’ve enhanced the Logs screen with the new Warning and Log filters to help you quickly find the logs you need. These additions complement the existing Fatal, Error, and Detail filters, making it easier to pinpoint specific events and troubleshoot issues efficiently.
TimescaleDB v2.18.2 on Timescale Cloud
New services created in Timescale Cloud now use TimescaleDB v2.18.2. Existing services are in the process of being automatically upgraded to this version.
This new release fixes a number of bugs including:
- Fix
ExplainHookbreaking the call chain. - Respect
ExecutorStarthooks of other extensions. - Block dropping internal compressed chunks with
drop_chunk().
SQL Assistant improvements
- Support for Claude 3.7 Sonnet and extended thinking including reasoning tokens.
- Ability to abort SQL Assistant requests while the response is streaming.
🤖 SQL Assistant Improvements and Pgai Docs Reorganization
February 21, 2025
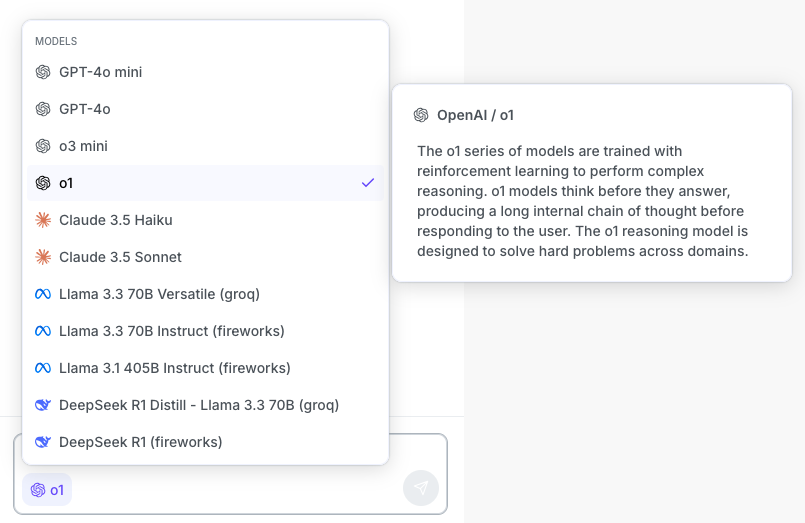
New models and improved UX for SQL Assistant
We have added fireworks.ai and Groq as service providers, and several new LLM options for SQL Assistant:
- OpenAI o1
- DeepSeek R1
- Llama 3.3 70B
- Llama 3.1 405B
- DeepSeek R1 Distill - Llama 3.3
We've also improved the model picker by adding descriptions for each model:
Updated and reorganized docs for pgai
We have improved the GitHub docs for pgai. Now relevant sections have been grouped into their own folders and we've created a comprehensive summary doc. Check it out here.
💘 TimescaleDB v2.18.1 and AWS Transit Gateway Support Generally Available
February 14, 2025
TimescaleDB v2.18.1
New services created in Timescale Cloud now use TimescaleDB v2.18.1. Existing services will be automatically upgraded in their next maintenance window starting next week.
This new release includes a number of bug fixes and small improvements including:
- Faster columnar scans when using the hypercore table access method
- Ensure all constraints are always applied when deleting data on the columnstore
- Pushdown all filters on scans for UPDATE/DELETE operations on the columnstore
AWS Transit Gateway support is now generally available!
Timescale Cloud now fully supports AWS Transit Gateway, making it even easier to securely connect your database to multiple VPCs across different environments—including AWS, on-prem, and other cloud providers.
With this update, you can establish a peering connection between your Timescale Cloud services and an AWS Transit Gateway in your AWS account. This keeps your Timescale Cloud services safely behind a VPC while allowing seamless access across complex network setups.
🤖 TimescaleDB v2.18 and SQL Assistant Improvements in Data Mode and PopSQL
February 6, 2025
TimescaleDB v2.18 - dense indexes in the columnstore and query vectorization improvements
Starting this week, all new services created on Timescale Cloud use TimescaleDB v2.18. Existing services will be upgraded gradually during their maintenance window.
Highlighted features in TimescaleDB v2.18.0 include:
- The ability to add dense indexes (btree and hash) to the columnstore through the new hypercore table access method.
- Significant performance improvements through vectorization (SIMD) for aggregations using a group by with one column and/or using a filter clause when querying the columnstore.
- Hypertables support triggers for transition tables, which is one of the most upvoted community feature requests.
- Updated methods to manage Timescale's hybrid row-columnar store (hypercore). These methods highlight columnstore usage. The columnstore includes an optimized columnar format as well as compression.
SQL Assistant improvements
We made a few improvements to SQL Assistant:
Dedicated SQL Assistant threads 🧵
Each query, notebook, and dashboard now gets its own conversation thread, keeping your chats organized.
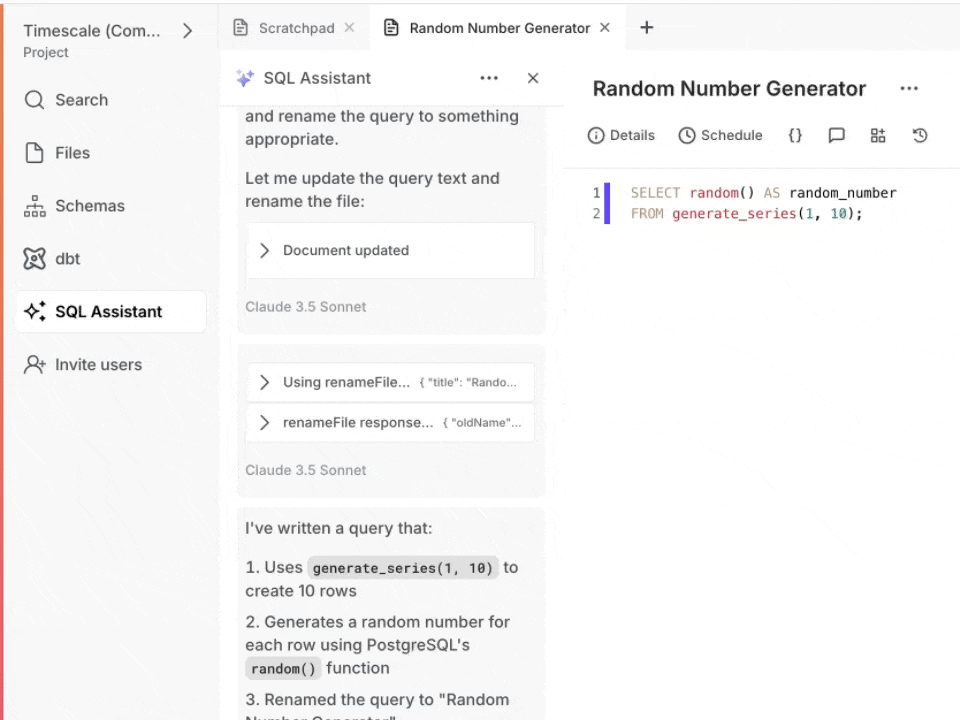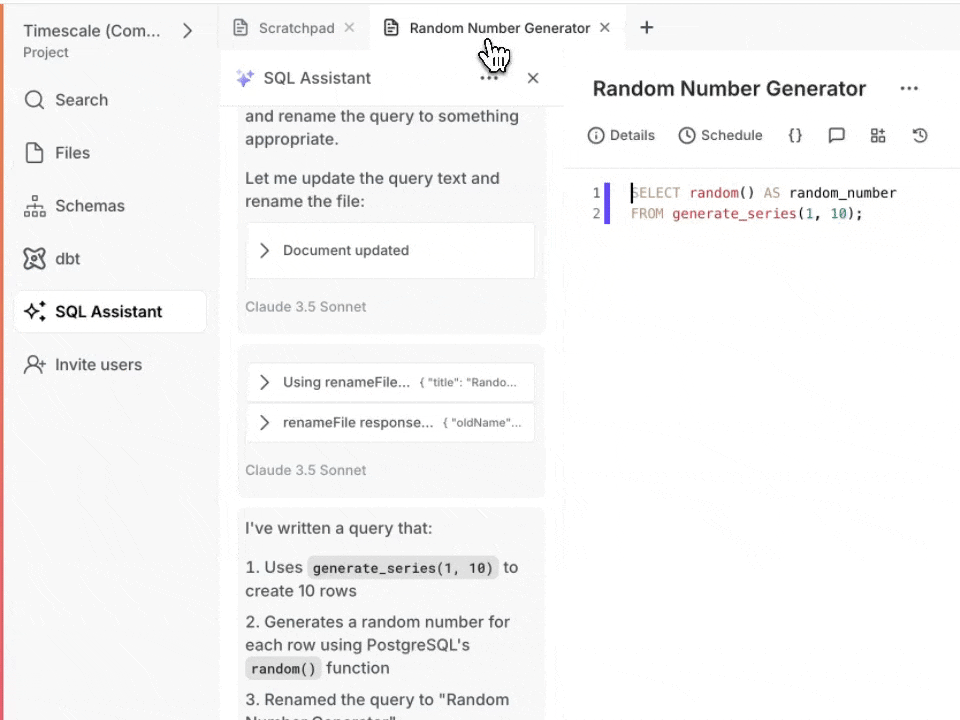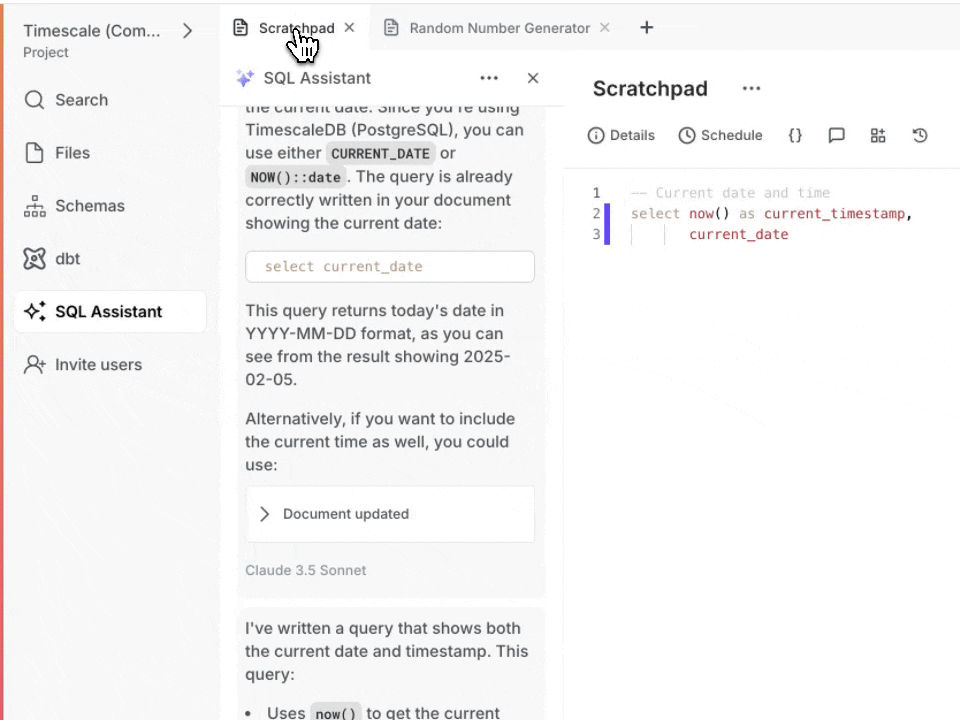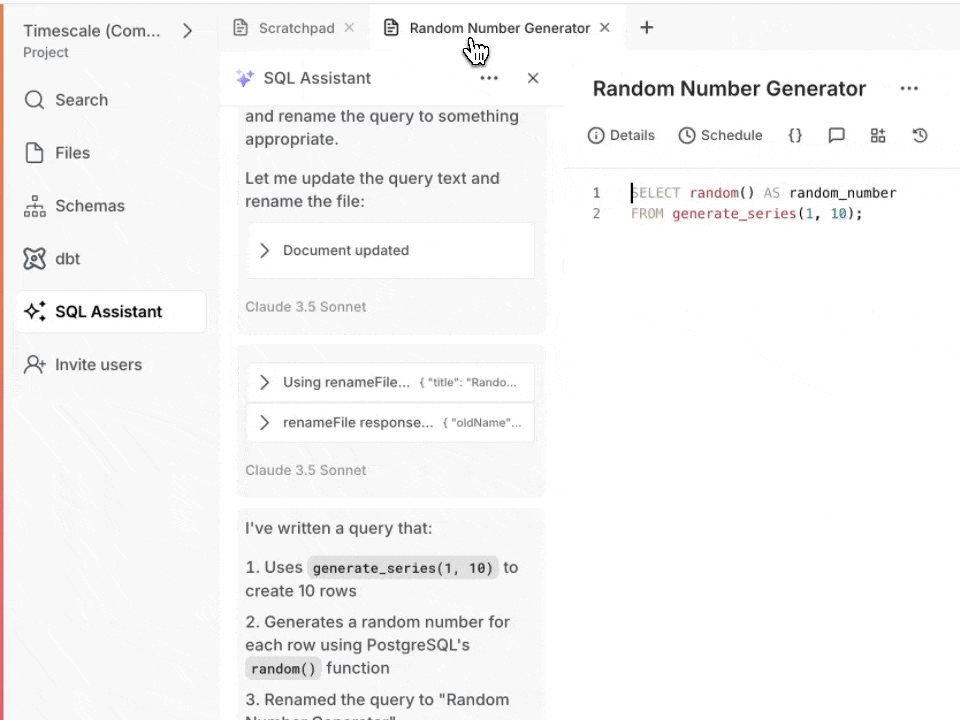
Delete messages ❌
Made a typo? Asked the wrong question? You can now delete individual messages from your thread to keep the conversation clean and relevant.
Support for OpenAI o3-mini ⚡
We’ve added support for OpenAI’s latest o3-mini model, bringing faster response times and improved reasoning for SQL queries.
🌐 IP Allowlists in Data Mode and PopSQL
January 31, 2025
For enhanced network security, you can now also create IP allowlists in the Timescale Console data mode and PopSQL. Similarly to the [ops mode IP allowlists][ops-mode-allow-list], this feature grants access to your data only to certain IP addresses. For example, you might require your employees to use a VPN and add your VPN static egress IP to the allowlist.
This feature is available in:
- [Timescale Console][console] data mode, for all pricing tiers
- [PopSQL web][popsql-web]
- [PopSQL desktop][popsql-desktop]
Enable this feature in PopSQL/Timescale Console data mode > Project > Settings > IP Allowlist:
🤖 pgai Extension and Python Library Updates
January 24, 2025
AI — pgai Postgres extension 0.7.0
This release enhances the Vectorizer functionality by adding configurable base_url support for OpenAI API. This enables pgai Vectorizer to use all OpenAI-compatible models and APIs via the OpenAI integration simply by changing the base_url. This release also includes public granting of vectorizers, superuser creation on any table, an upgrade to the Ollama client to 0.4.5, a new docker-start command, and various fixes for struct handling, schema qualification, and system package management. See all changes on Github.
AI - pgai python library 0.5.0
This release adds comprehensive SQLAlchemy and Alembic support for vector embeddings, including operations for migrations and improved model inheritance patterns. You can now seamlessly integrate vector search capabilities with SQLAlchemy models while utilizing Alembic for database migrations. This release also adds key improvements to the Ollama integration and self-hosted Vectorizer configuration. See all changes on Github.
AWS Transit Gateway Support
January 17, 2025
AWS Transit Gateway Support (Early Access)
Timescale Cloud now enables you to connect to your Timescale Cloud services through AWS Transit Gateway. This feature is available to Scale and Enterprise customers. It will be in Early Access for a short time and available in the Timescale Console very soon. If you are interested in implementing this Early Access Feature, reach out to your Rep.
🇮🇳 New region in India, Postgres 17 upgrades, and TimescaleDB on AWS Marketplace
January 10, 2025
Welcome India! (Support for a new region: Mumbai)
Timescale Cloud now supports the Mumbai region. Starting today, you can run Timescale Cloud services in Mumbai, bringing our database solutions closer to users in India.
Postgres major version upgrades to PG 17
Timescale Cloud services can now be upgraded directly to Postgres 17 from versions 14, 15, or 16. Users running versions 12 or 13 must first upgrade to version 15 or 16, before upgrading to 17.
Timescale Cloud available on AWS Marketplace
Timescale Cloud is now available in the [AWS Marketplace][aws-timescale]. This allows you to keep billing centralized on your AWS account, use your already committed AWS Enterprise Discount Program spend to pay your Timescale Cloud bill and simplify procurement and vendor management.
🎅 Postgres 17, feature requests, and Postgres Livesync
December 20, 2024
Postgres 17
All new Timescale Cloud services now come with Postgres 17.2, the latest version. Upgrades to Postgres 17 for services running on prior versions will be available in January. Postgres 17 adds new capabilities and improvements to Timescale like:
- System-wide Performance Improvements. Significant performance boosts, particularly in high-concurrency workloads. Enhancements in the I/O layer, including improved Write-Ahead Log (WAL) processing, can result in up to a 2x increase in write throughput under heavy loads.
- Enhanced JSON Support. The new JSON_TABLE allows developers to convert JSON data directly into relational tables, simplifying the integration of JSON and SQL. The release also adds new SQL/JSON constructors and query functions, offering powerful tools to manipulate and query JSON data within a traditional relational schema.
- More Flexible MERGE Operations. The MERGE command now includes a RETURNING clause, making it easier to track and work with modified data. You can now also update views using MERGE, unlocking new use cases for complex queries and data manipulation.
Submit feature requests from Timescale Console
You can now submit feature requests directly from Console and see the list of feature requests you have made. Just click on Feature Requests on the right sidebar.
All feature requests are automatically published to the Timescale Forum and are reviewed by the product team, providing more visibility and transparency on their status as well as allowing other customers to vote for them.
Postgres Livesync (Alpha release)
We have built a new solution that helps you continuously replicate all or some of your Postgres tables directly into Timescale Cloud.
Livesync allows you to keep a current Postgres instance such as RDS as your primary database, and easily offload your real-time analytical queries to Timescale Cloud to boost their performance. If you have any questions or feedback, talk to us in #livesync in Timescale Community.
This is just the beginning—you'll see more from livesync in 2025!
In-Console import from S3, I/O Boost, and Jobs Explorer
December 13, 2024
In-Console import from S3 (CSV and Parquet files)
Connect your S3 buckets to import data into Timescale Cloud. We support CSV (including .zip and .gzip) and Parquet files, with a 10 GB size limit in this initial release. This feature is accessible in the Import your data section right after service creation and through the Actions tab.
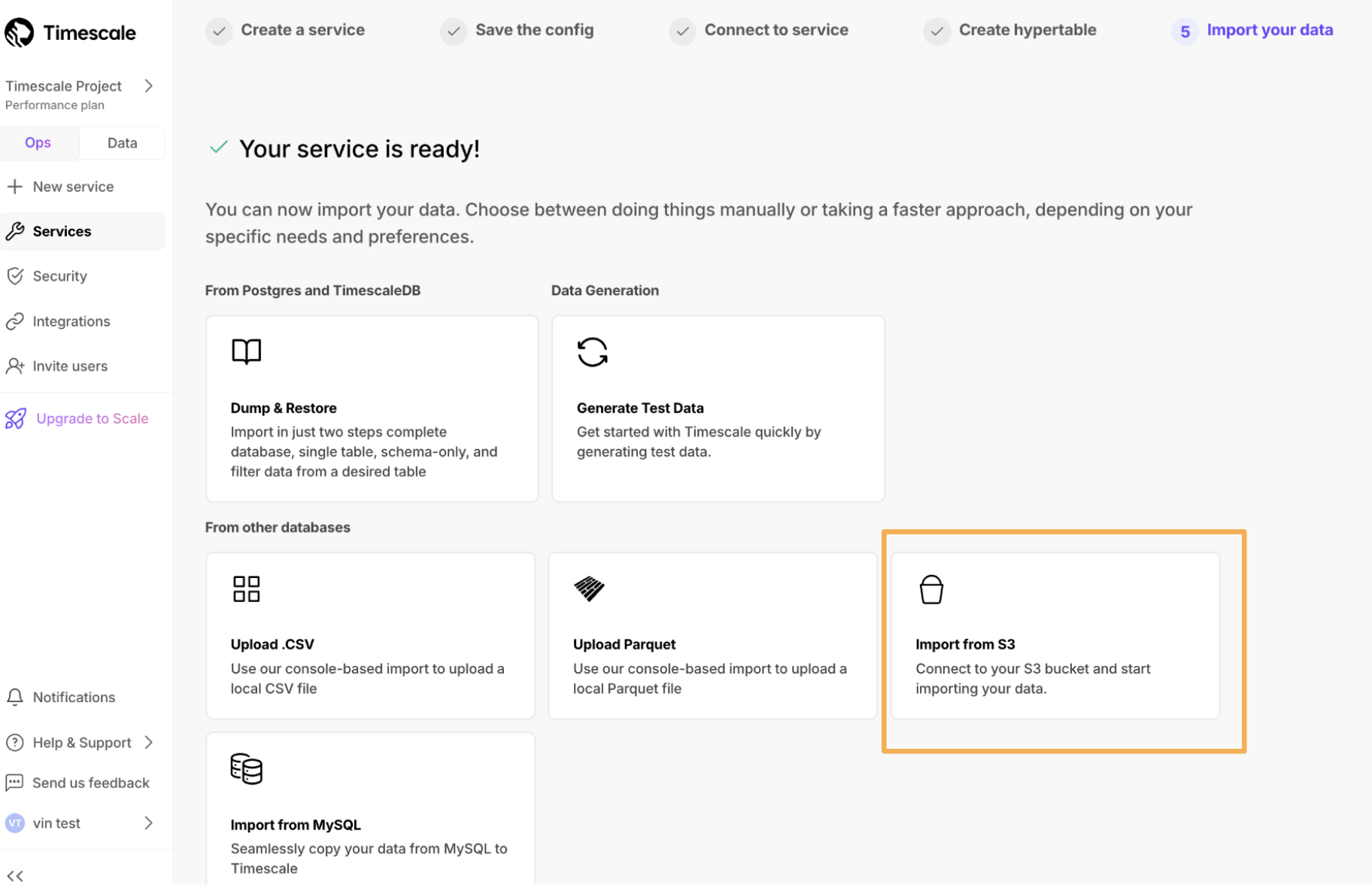
Self-Serve I/O Boost 📈
I/O Boost is an add-on for customers on Scale or Enterprise tiers that maximizes the I/O capacity of EBS storage to 16,000 IOPS and 1,000 MBps throughput per service. To enable I/O Boost, navigate to Services > Operations in Timescale Console. A simple toggle allows you to enable the feature, with pricing clearly displayed at $0.41/hour per node.
See all the jobs associated with your service through a new Jobs tab. You can see the type of job, its status (Running, Paused, and others), and a detailed history of the last 100 runs, including success rates and runtime statistics.
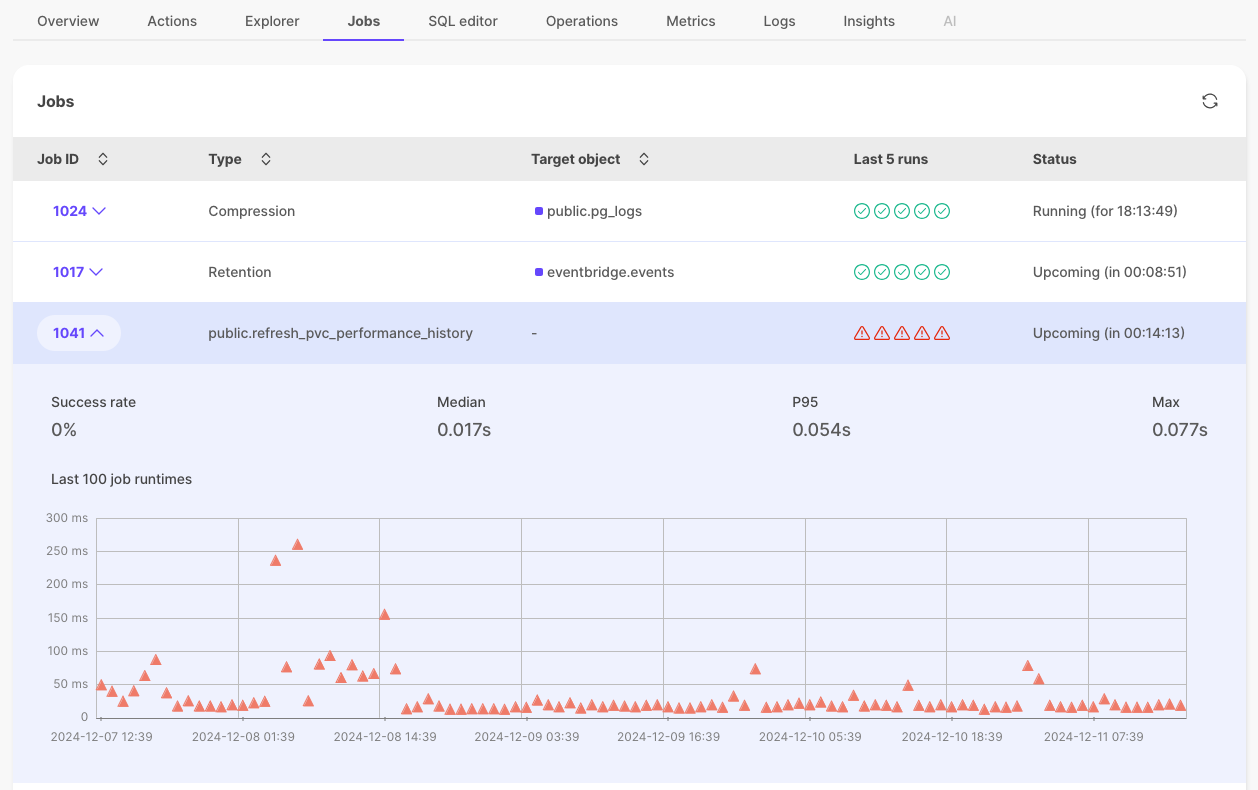
🛝 New service creation flow
December 6, 2024
- AI and Vector: the UI now lets you choose an option for creating AI and Vector-ready services right from the start. You no longer need to add the pgai, pgvector, and pgvectorscale extensions manually. You can combine this with time-series capabilities as well!
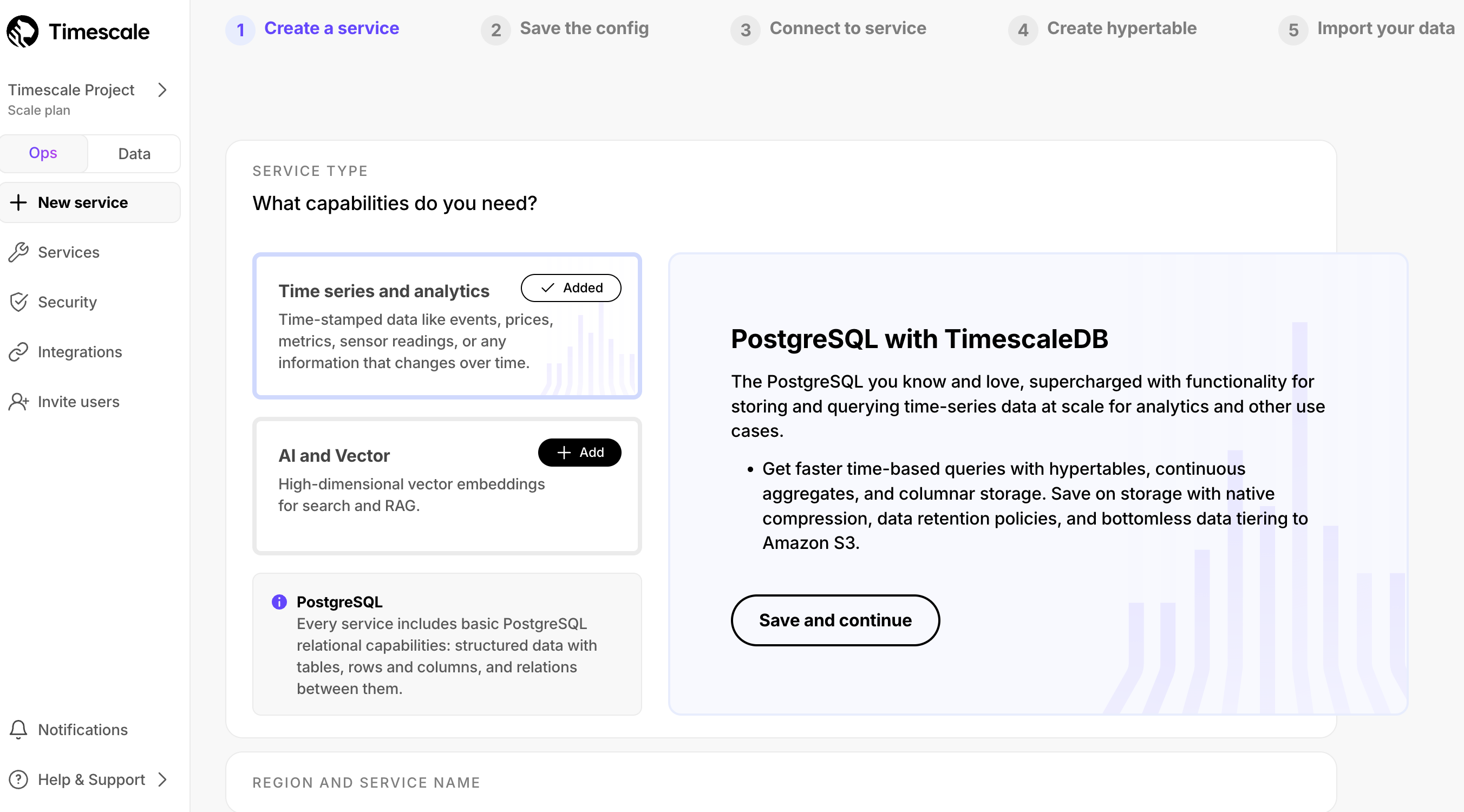
- Compute size recommendations: new (and old) users were sometimes unsure about what compute size to use for their workload. We now offer compute size recommendations based on how much data you plan to have in your service.
- More information about configuration options: we've made it clearer what each configuration option does, so that you can make more informed choices about how you want your service to be set up.
🗝️ IP Allow Lists!
November 21, 2024
IP Allow Lists let you specify a list of IP addresses that have access to your Timescale Cloud services and block any others. IP Allow Lists are a lightweight but effective solution for customers concerned with security and compliance. They enable you to prevent unauthorized connections without the need for a Virtual Private Cloud (VPC).
To get started, in Timescale Console, select a service, then click Operations > Security > IP Allow List, then create an IP Allow List.
For more information, see our docs.
🤩 SQL Assistant, TimescaleDB v2.17, HIPAA compliance, and better logging
November 14, 2024
🤖 New AI companion: SQL Assistant
SQL Assistant uses AI to help you write SQL faster and more accurately.
- Real-time help: chat with models like OpenAI 4o and Claude 3.5 Sonnet to get help writing SQL. Describe what you want in natural language and have AI write the SQL for you.
- Error resolution: when you run into an error, SQL Assistant proposes a recommended fix that you can choose to accept.
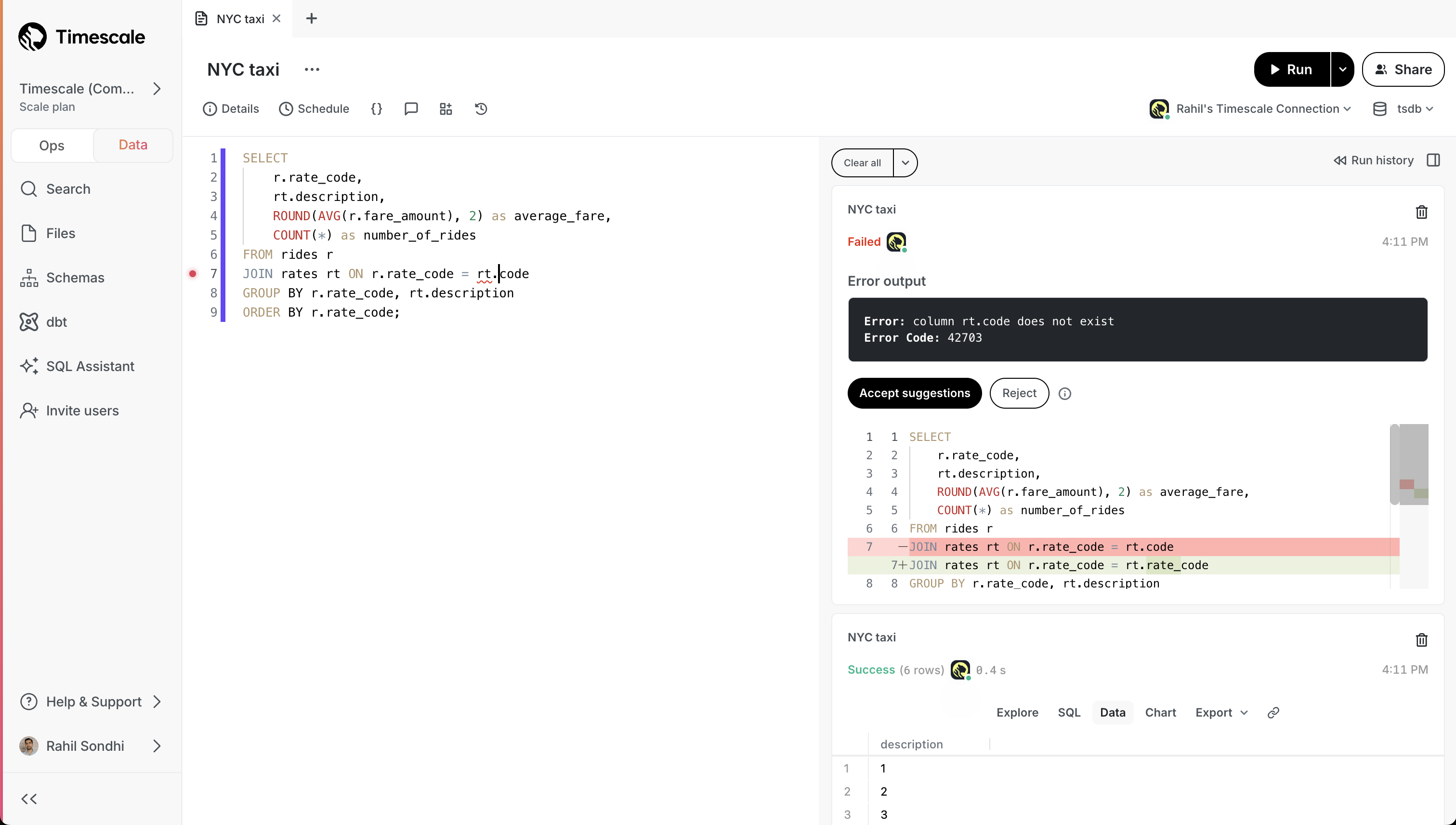
- Generate titles and descriptions: click a button and SQL Assistant generates a title and description for your query. No more untitled queries!
See our blog post or docs for full details!
🏄 TimescaleDB v2.17 - performance improvements for analytical queries and continuous aggregate refreshes
Starting this week, all new services created on Timescale Cloud use TimescaleDB v2.17. Existing services are upgraded gradually during their maintenance windows.
TimescaleDB v2.17 significantly improves the performance of continuous aggregate refreshes, and contains performance improvements for analytical queries and delete operations over compressed hypertables.
Best practice is to upgrade at the next available opportunity.
Highlighted features in TimescaleDB v2.17 are:
Significant performance improvements for continuous aggregate policies:
Continuous aggregate refresh now uses
mergeinstead of deleting old materialized data and re-inserting.Continuous aggregate policies are now more lightweight, use less system resources, and complete faster. This update:
Decreases dramatically the amount of data that must be written on the continuous aggregate in the presence of a small number of changes
- Reduces the i/o cost of refreshing a continuous aggregate
- Generates fewer Write-Ahead Logs (
WAL)
Increased performance for real-time analytical queries over compressed hypertables:
We are excited to introduce additional Single Instruction, Multiple Data (SIMD) vectorization optimization to TimescaleDB. This release supports vectorized execution for queries that group by using the
segment_bycolumn(s), and aggregate using thesum,count,avg,min, andmaxbasic aggregate functions.Stay tuned for more to come in follow-up releases! Support for grouping on additional columns, filtered aggregation, vectorized expressions, and
time_bucketis coming soon.Improved performance of deletes on compressed hypertables when a large amount of data is affected.
This improvement speeds up operations that delete whole segments by skipping the decompression step. It is enabled for all deletes that filter by the segment_by column(s).
Timescale Cloud's Enterprise plan is now HIPAA (Health Insurance Portability and Accountability Act) compliant. This allows organizations to securely manage and analyze sensitive healthcare data, ensuring they meet regulatory requirements while building compliant applications.
Expanded logging within Timescale Console
Customers can now access more than just the most recent 500 logs within the Timescale Console. We've updated the user experience, including scrollbar with infinite scrolling capabilities.
✨ Connect to Timescale from .NET Stack and check status of recent jobs
November 07, 2024
Connect to Timescale with your .NET stack
We've added instructions for connecting to Timescale using your .NET workflow. In Console after service creation, or in the Actions tab, you can now select .NET from the developer library list. The guide demonstrates how to use Npgsql to integrate Timescale with your existing software stack.
✅ Last 5 jobs status
In the Jobs section of the Explorer, users can now see the status (completed/failed) of the last 5 runs of each job.
🎃 New AI, data integration, and performance enhancements
October 31, 2024
Pgai Vectorizer: vector embeddings as database indexes (early access)
This early access feature enables you to automatically create, update, and maintain embeddings as your data changes. Just like an index, Timescale handles all the complexity: syncing, versioning, and cleanup happen automatically. This means no manual tracking, zero maintenance burden, and the freedom to rapidly experiment with different embedding models and chunking strategies without building new pipelines. Navigate to the AI tab in your service overview and follow the instructions to add your OpenAI API key and set up your first vectorizer or read our guide to automate embedding generation with pgai Vectorizer for more details.

Postgres-to-Postgres foreign data wrappers:
Fetch and query data from multiple Postgres databases, including time-series data in hypertables, directly within Timescale Cloud using foreign data wrappers (FDW). No more complicated ETL processes or external tools—just seamless integration right within your SQL editor. This feature is ideal for developers who manage multiple Postgres and time-series instances and need quick, easy access to data across databases.
Faster queries over tiered data
This release adds support for runtime chunk exclusion for queries that need to access tiered storage. Chunk exclusion now works with queries that use stable expressions in the WHERE clause. The most common form of this type of query is:
For more info on queries with immutable/stable/volatile filters, check our blog post on Implementing constraint exclusion for faster query performance.
If you no longer want to use tiered storage for a particular hypertable, you can now disable tiering and drop the associated tiering metadata on the hypertable with a call to disable_tiering function.
Chunk interval recommendations
Timescale Console now shows recommendations for services with too many small chunks in their hypertables. Recommendations for new intervals that improve service performance are displayed for each underperforming service and hypertable. Users can then change their chunk interval and boost performance within Timescale Console.

💡 Help with hypertables and faster notebooks
October 18, 2024
🧙Hypertable creation wizard
After creating a service, users can now create a hypertable directly in Timescale Console by first creating a table, then converting it into a hypertable. This is possible using the in-console SQL editor. All standard hypertable configuration options are supported, along with any customization of the underlying table schema.
🍭 PopSQL Notebooks
The newest version of Data Mode Notebooks is now waaaay faster. Why? We've incorporated the newly developed v3 of our query engine that currently powers Timescale Console's SQL Editor. Check out the difference in query response times.
✨ Production-Ready Low-Downtime Migrations, MySQL Import, Actions Tab, and Current Lock Contention Visibility in SQL Editor
October 10, 2024
🏗️ Live Migrations v1.0 Release
Last year, we began developing a solution for low-downtime migration from Postgres and TimescaleDB. Since then, this solution has evolved significantly, featuring enhanced functionality, improved reliability, and performance optimizations. We're now proud to announce that live migration is production-ready with the release of version 1.0.
Many of our customers have successfully migrated databases to Timescale using live migration, with some databases as large as a few terabytes in size.
As part of the service creation flow, we offer the following:
- Connect to services from different sources
- Import and migrate data from various sources
- Create hypertables
Previously, these actions were only visible during the service creation process and couldn't be accessed later. Now, these actions are persisted within the service, allowing users to leverage them on-demand whenever they're ready to perform these tasks.
🧭 Import Data from MySQL
We've noticed users struggling to convert their MySQL schema and data into their Timescale Cloud services. This was due to the semantic differences between MySQL and Postgres. To simplify this process, we now offer easy-to-follow instructions to import data from MySQL to Timescale Cloud. This feature is available as part of the data import wizard, under the Import from MySQL option.
🔐 Current Lock Contention
In Timescale Console, we offer the SQL editor so you can directly querying your service. As a new improvement, if a query is waiting on locks and can't complete execution, Timescale Console now displays the current lock contention in the results section .
CIDR & VPC Updates
October 3, 2024
Timescale now supports multiple CIDRs on the customer VPC. Customers who want to take advantage of multiple CIDRs will need to recreate their peering.
🤝 New modes in Timescale Console: Ops and Data mode, and Console based Parquet File Import
September 19, 2024
We've been listening to your feedback and noticed that Timescale Console users have diverse needs. Some of you are focused on operational tasks like adding replicas or changing parameters, while others are diving deep into data analysis to gather insights.
To better serve you, we've introduced new modes to the Timescale Console UI—tailoring the experience based on what you're trying to accomplish.
Ops mode is where you can manage your services, add replicas, configure compression, change parameters, and so on.
Data mode is the full PopSQL experience: write queries with autocomplete, visualize data with charts and dashboards, schedule queries and dashboards to create alerts or recurring reports, share queries and dashboards, and more.
Try it today and let us know what you think!
Console based Parquet File Import
Now users can upload from Parquet to Timescale Cloud by uploading the file from their local file system. For files larger than 250 MB, or if you want to do it yourself, follow the three-step process to upload Parquet files to Timescale.
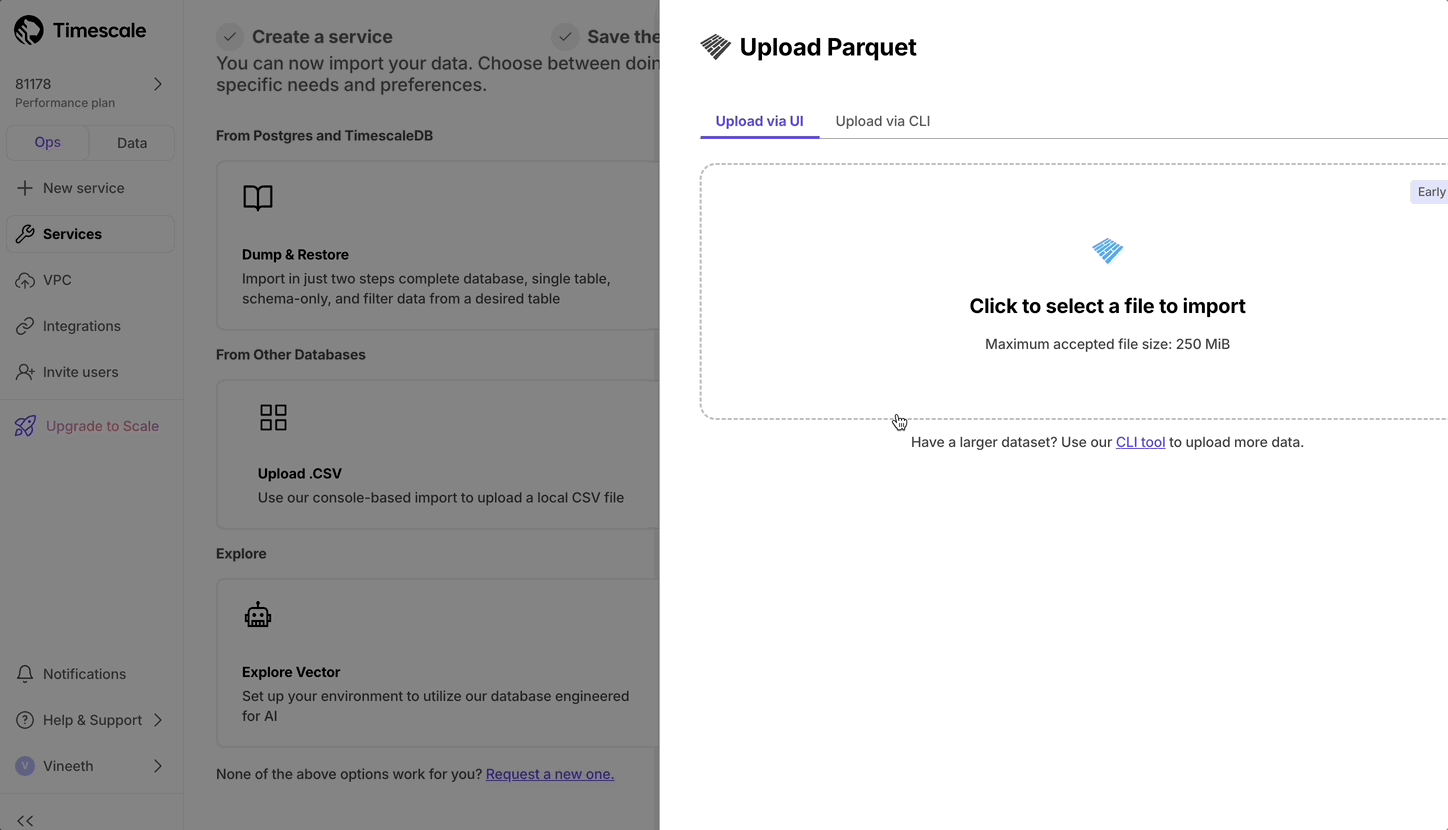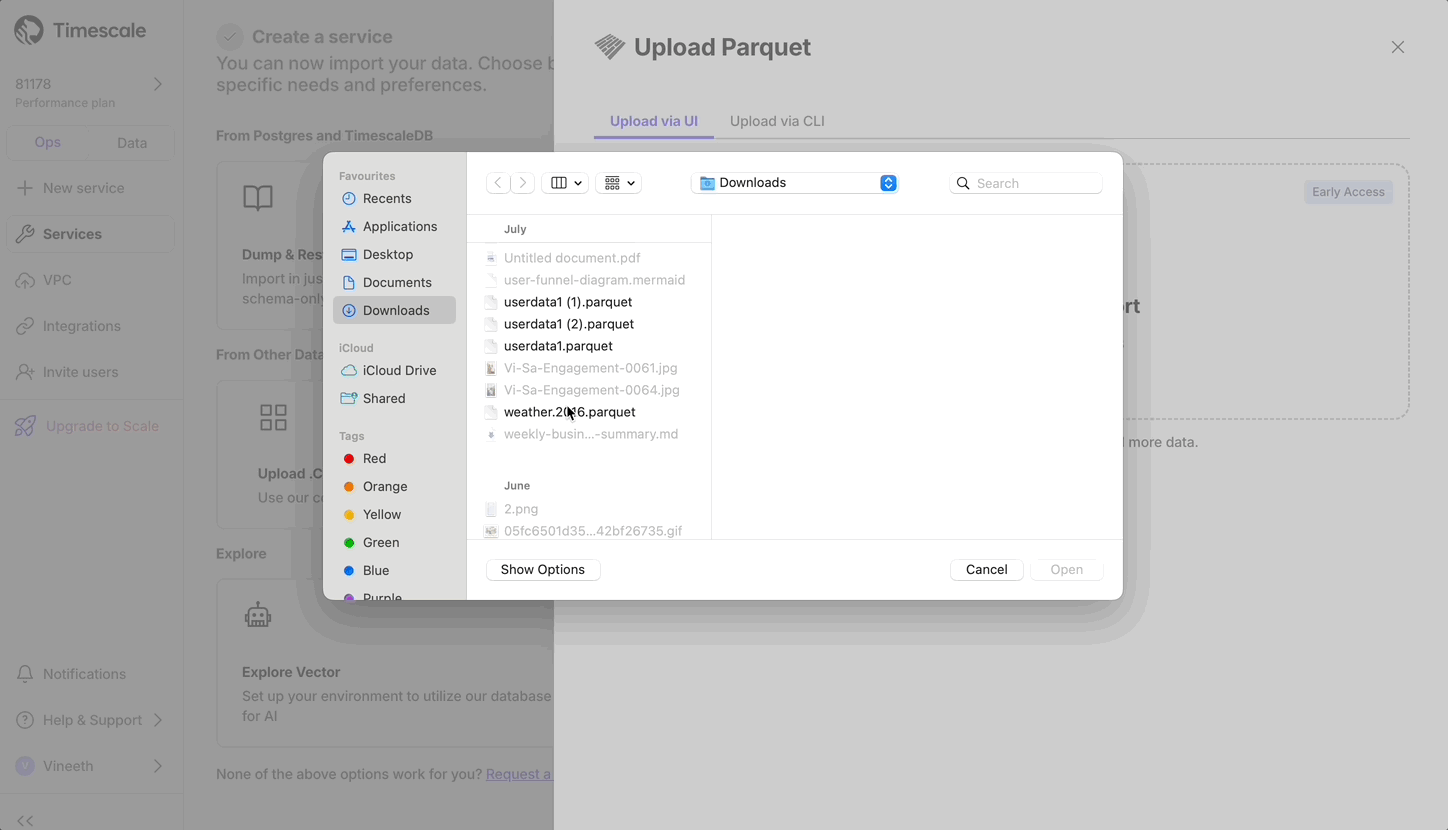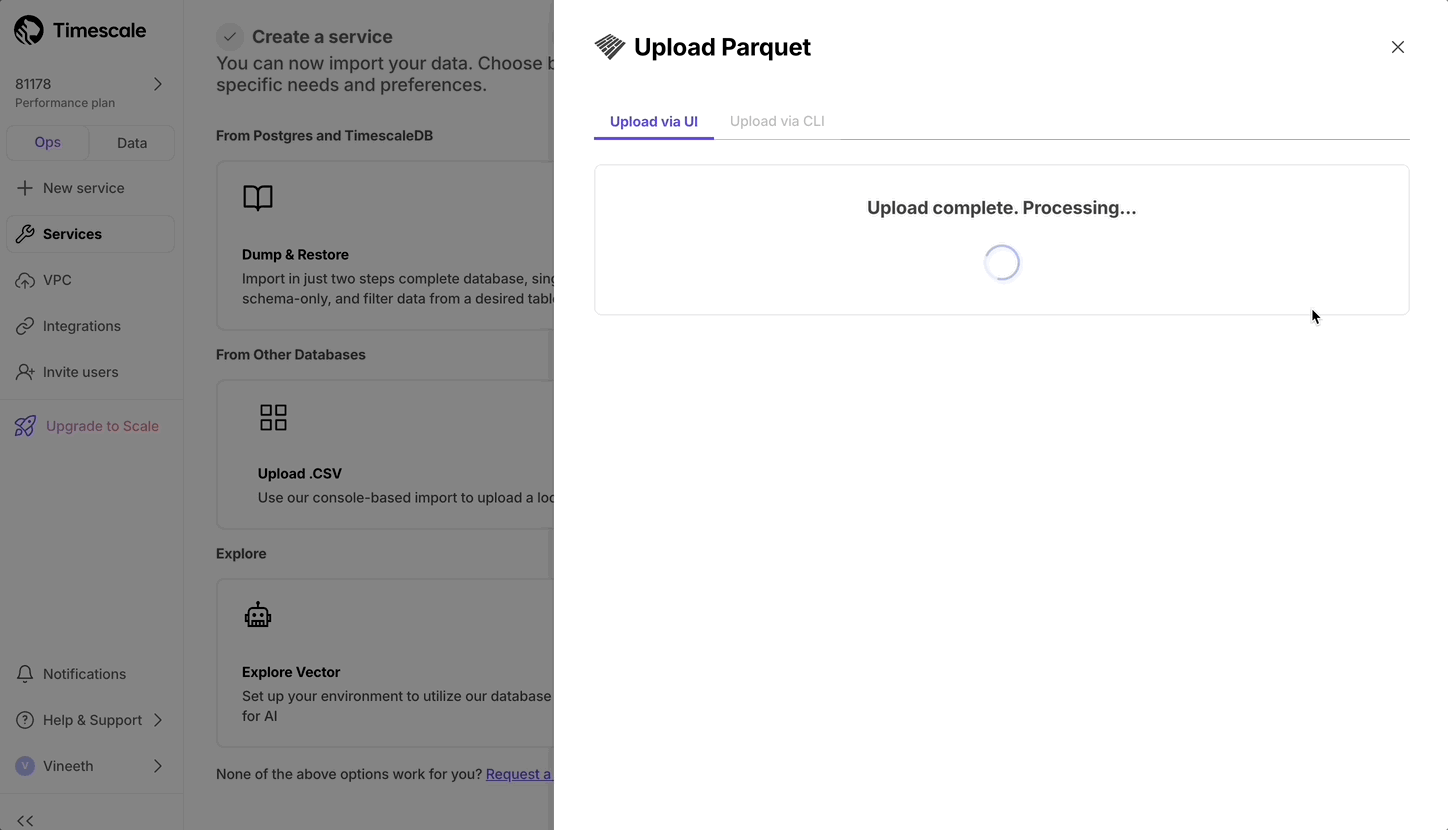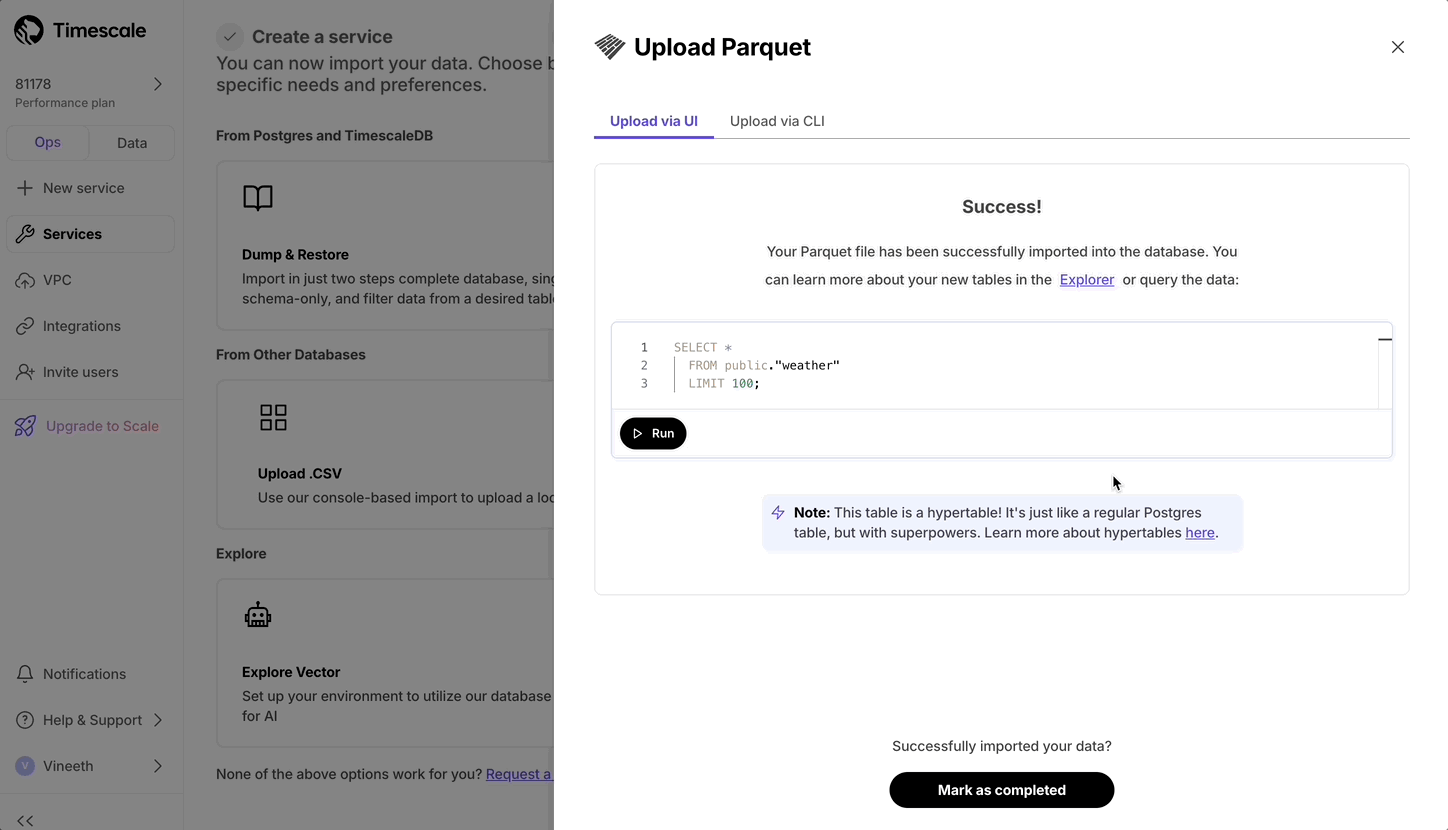
SQL editor improvements
- In the Ops mode SQL editor, you can now highlight a statement to run a specific statement.
High availability, usability, and migrations improvements
September 12, 2024
Multiple HA replicas
Scale and Enterprise customers can now configure two new multiple high availability (HA) replica options directly through Timescale Console:
- Two HA replicas (both asynchronous) - our highest availability configuration.
- Two HA replicas (one asynchronous, one synchronous) - our highest data integrity configuration.
Previously, Timescale offered only a single synchronous replica for customers seeking high availability. The single HA option is still available.


For more details on multiple HA replicas, see Manage high availability.
Other improvements
- In the Console SQL editor, we now indicate if your database session is healthy or has been disconnected. If it's been disconnected, the session will reconnect on your next query execution.

- Released live-migration v0.0.26 and then v0.0.27 which includes multiple performance improvements and bugfixes as well as better support for Postgres 12.
One-click SQL statement execution from Timescale Console, and session support in the SQL editor
September 05, 2024
One-click SQL statement execution from Timescale Console
Now you can simply click to run SQL statements in various places in the Console. This requires that the [SQL Editor][sql-editor] is enabled for the service.
Enable Continuous Aggregates from the CAGGs wizard by clicking Run below the SQL statement.

Enable database extensions by clicking Run below the SQL statement.

Query data instantly with a single click in the Console after successfully uploading a CSV file.

Session support in the SQL editor
Last week we announced the new in-console SQL editor. However, there was a limitation where a new database session was created for each query execution.
Today we removed that limitation and added support for keeping one database session for each user logged in, which means you can do things like start transactions:
Or work with temporary tables:
Or use the set command:
😎 Query your database directly from the Console and enhanced data import and migration options
August 30, 2024
SQL Editor in Timescale Console
We've added a new tab to the service screen that allows users to query their database directly, without having to leave the console interface.
- For existing services on Timescale, this is an opt-in feature. For all newly created services, the SQL Editor will be enabled by default.
- Users can disable the SQL Editor at any time by toggling the option under the Operations tab.
- The editor supports all DML and DDL operations (any single-statement SQL query), but doesn't support multiple SQL statements in a single query.

Enhanced Data Import Options for Quick Evaluation
After service creation, we now offer a dedicated section for data import, including options to import from Postgres as a source or from CSV files.
The enhanced Postgres import instructions now offer several options: single table import, schema-only import, partial data import (allowing selection of a specific time range), and complete database import. Users can execute any of these data imports with just one or two simple commands provided in the data import section.

Improvements to Live migration
We've released v0.0.25 of Live migration that includes the following improvements:
- Support migrating tsdb on non public schema to public schema
- Pre-migration compatibility checks
- Docker compose build fixes
🛠️ Improved tooling in Timescale Cloud and new AI and Vector extension releases
August 22, 2024
CSV import
We have added a CSV import tool to the Timescale Console. For all TimescaleDB services, after service creation you can:
- Choose a local file
- Select the name of the data collection to be uploaded (default is file name)
- Choose data types for each column
- Upload the file as a new hypertable within your service
Look for the
Import data from .csvtile in theImport your datastep of service creation.

Replica lag
Customers now have more visibility into the state of replicas running on Timescale Cloud. We’ve released a new parameter called Replica Lag within the Service Overview for both Read and High Availability Replicas. Replica lag is measured in bytes against the current state of the primary database. For questions or concerns about the relative lag state of your replica, reach out to Customer Support.

Adjust chunk interval
Customers can now adjust their chunk interval for their hypertables and continuous aggregates through the Timescale UI. In the Explorer, select the corresponding hypertable you would like to adjust the chunk interval for. Under Chunk information, you can change the chunk interval. Note that this only changes the chunk interval going forward, and does not retroactively change existing chunks.

CloudWatch permissions via role assumption
We've released permission granting via role assumption to CloudWatch. Role assumption is both more secure and more convenient for customers who no longer need to rotate credentials and update their exporter config.
For more details take a look at [our documentation][integrations].

Two-factor authentication (2FA) indicator
We’ve added a 2FA status column to the Members page, allowing customers to easily see whether each project member has 2FA enabled or disabled.

Anthropic and Cohere integrations in pgai
The pgai extension v0.3.0 now supports embedding creation and LLM reasoning using models from Anthropic and Cohere. For details and examples, see this post for pgai and Cohere, and this post for pgai and Anthropic.
pgvectorscale extension: ARM builds and improved recall for low dimensional vectors
pgvectorscale extension v0.3.0 adds support for ARM processors and improves recall when using StreamingDiskANN indexes with low dimensionality vectors. We recommend updating to this version if you are self-hosting.
🏄 Optimizations for compressed data and extended join support in continuous aggregates
August 15, 2024
TimescaleDB v2.16.0 contains significant performance improvements when working with compressed data, extended join support in continuous aggregates, and the ability to define foreign keys from regular tables towards hypertables. We recommend upgrading at the next available opportunity.
Any new service created on Timescale Cloud starting today uses TimescaleDB v2.16.0.
In TimescaleDB v2.16.0 we:
- Introduced multiple performance focused optimizations for data manipulation operations (DML) over compressed chunks.
Improved upsert performance by more than 100x in some cases and more than 500x in some update/delete scenarios.
- Added the ability to define chunk skipping indexes on non-partitioning columns of compressed hypertables.
TimescaleDB v2.16.0 extends chunk exclusion to use these skipping (sparse) indexes when queries filter on the relevant columns, and prune chunks that do not include any relevant data for calculating the query response.
- Offered new options for use cases that require foreign keys defined.
You can now add foreign keys from regular tables towards hypertables. We have also removed some really annoying locks in the reverse direction that blocked access to referenced tables while compression was running.
- Extended Continuous Aggregates to support more types of analytical queries.
More types of joins are supported, additional equality operators on join clauses, and support for joins between multiple regular tables.
Highlighted features in this release
- Improved query performance through chunk exclusion on compressed hypertables.
You can now define chunk skipping indexes on compressed chunks for any column with one of the following
integer data types: smallint, int, bigint, serial, bigserial, date, timestamp, timestamptz.
After calling enable_chunk_skipping on a column, TimescaleDB tracks the min and max values for
that column, using this information to exclude chunks for queries filtering on that
column, where no data would be found.
- Improved upsert performance on compressed hypertables.
By using index scans to verify constraints during inserts on compressed chunks, TimescaleDB speeds up some ON CONFLICT clauses by more than 100x.
- Improved performance of updates, deletes, and inserts on compressed hypertables.
By filtering data while accessing the compressed data and before decompressing, TimescaleDB has improved performance for updates and deletes on all types of compressed chunks, as well as inserts into compressed chunks with unique constraints.
By signaling constraint violations without decompressing, or decompressing only when matching records are found in the case of updates, deletes and upserts, TimescaleDB v2.16.0 speeds up those operations more than 1000x in some update/delete scenarios, and 10x for upserts.
You can add foreign keys from regular tables to hypertables, with support for all types of cascading options. This is useful for hypertables that partition using sequential IDs, and need to reference these IDs from other tables.
Lower locking requirements during compression for hypertables with foreign keys
Advanced foreign key handling removes the need for locking referenced tables when new chunks are compressed. DML is no longer blocked on referenced tables while compression runs on a hypertable.
- Improved support for queries on Continuous Aggregates
INNER/LEFT and LATERAL joins are now supported. Plus, you can now join with multiple regular tables,
and have more than one equality operator on join clauses.
Postgres 13 support removal announcement
Following the deprecation announcement for Postgres 13 in TimescaleDB v2.13, Postgres 13 is no longer supported in TimescaleDB v2.16.
The currently supported Postgres major versions are 14, 15, and 16.
📦 Performance, packaging and stability improvements for Timescale Cloud
August 8, 2024
New plans
To support evolving customer needs, Timescale Cloud now offers three plans to provide more value, flexibility, and efficiency.
- Performance: for cost-focused, smaller projects. No credit card required to start.
- Scale: for developers handling critical and demanding apps.
- Enterprise: for enterprises with mission-critical apps.
Each plan continues to bill based on hourly usage, primarily for compute you run and storage you consume. You can upgrade or downgrade between Performance and Scale plans via the Console UI at any time. More information about the specifics and differences between these pricing plans can be found here in the docs.
Improvements to the Timescale Console
The individual tiles on the services page have been enhanced with new information, including high-availability status. This will let you better assess the state of your services at a glance.
Live migration release v0.0.24
Improvements:
- Automatic retries are now available for the initial data copy of the migration
- Now uses pgcopydb for initial data copy for PG to TSDB migrations also (already did for TS to TS) which has a significant performance boost.
- Fixes issues with TimescaleDB v2.13.x migrations
- Support for chunk mapping for hypertables with custom schema and table prefixes
⚡ Performance and stability improvements for Timescale Cloud and TimescaleDB
July 12, 2024
The following improvements have been made to Timescale products:
Timescale Cloud:
- The connection pooler has been updated and now avoids multiple reloads
- The tsdbadmin user can now grant the following roles to other users:
pg_checkpoint,pg_monitor,pg_signal_backend,pg_read_all_stats,pg_stat_scan_tables - Timescale Console is far more reliable.
TimescaleDB
- The TimescaleDB v2.15.3 patch release improves handling of multiple unique indexes in a compressed INSERT, removes the recheck of ORDER when querying compressed data, improves memory management in DML functions, improves the tuple lock acquisition for tiered chunks on replicas, and fixes an issue with ORDER BY/GROUP BY in our HashAggregate optimization on PG16. For more information, see the release note.
- The TimescaleDB v2.15.2 patch release improves sort pushdown for partially compressed chunks, and compress_chunk with a primary space partition. The metadata function is removed from the update script, and hash partitioning on a primary column is disallowed. For more information, see the release note.
⚡ Performance improvements for live migration to Timescale Cloud
June 27, 2024
The following improvements have been made to the Timescale live-migration docker image:
- Table-based filtering is now available during live migration.
- Improvements to pbcopydb increase performance and remove unhelpful warning messages.
- The user notification log enables you to always select the most recent release for a migration run.
For improved stability and new features, update to the latest timescale/live-migration docker image. To learn more, see the live migration docs.
🦙Ollama integration in pgai
June 21, 2024
Ollama is now integrated with pgai.
Ollama is the easiest and most popular way to get up and running with open-source language models. Think of Ollama as Docker for LLMs, enabling easy access and usage of a variety of open-source models like Llama 3, Mistral, Phi 3, Gemma, and more.
With the pgai extension integrated in your database, embed Ollama AI into your app using SQL. For example:
To learn more, see the pgai Ollama documentation.
🧙 Compression Wizard
June 13, 2024
The compression wizard is now available on Timescale Cloud. Select a hypertable and be guided through enabling compression through the UI!
To access the compression wizard, navigate to Explorer, and select the hypertable you would like to compress. In the top right corner, hover where it says Compression off, and open the wizard. You will then be guided through the process of configuring compression for your hypertable, and can compress it directly through the UI.

🏎️💨 High Performance AI Apps With pgvectorscale
June 11, 2024
The [vectorscale extension][pgvectorscale] is now available on [Timescale Cloud][signup].
pgvectorscale complements pgvector, the open-source vector data extension for Postgres, and introduces the following key innovations for pgvector data:
- A new index type called StreamingDiskANN, inspired by the DiskANN algorithm, based on research from Microsoft.
- Statistical Binary Quantization: developed by Timescale researchers, This compression method improves on standard Binary Quantization.
On benchmark dataset of 50 million Cohere embeddings (768 dimensions each), Postgres with pgvector and pgvectorscale achieves 28x lower p95 latency and 16x higher query throughput compared to Pinecone's storage optimized (s1) index for approximate nearest neighbor queries at 99% recall, all at 75% less cost when self-hosted on AWS EC2.
To learn more, see the [pgvectorscale documentation][pgvectorscale].
🧐Integrate AI Into Your Database Using pgai
June 11, 2024
The [pgai extension][pgai] is now available on [Timescale Cloud][signup].
pgai brings embedding and generation AI models closer to the database. With pgai, you can now do the following directly from within Postgres in a SQL query:
- Create embeddings for your data.
- Retrieve LLM chat completions from models like OpenAI GPT4o.
- Reason over your data and facilitate use cases like classification, summarization, and data enrichment on your existing relational data in Postgres.
To learn more, see the [pgai documentation][pgai].
🐅Continuous Aggregate and Hypertable Improvements for TimescaleDB
June 7, 2024
The 2.15.x releases contains performance improvements and bug fixes. Highlights in these releases are:
- Continuous Aggregate now supports
time_bucketwith origin and/or offset. - Hypertable compression has the following improvements:
- Recommend optimized defaults for segment by and order by when configuring compression through analysis of table configuration and statistics.
- Added planner support to check more kinds of WHERE conditions before decompression. This reduces the number of rows that have to be decompressed.
- You can now use minmax sparse indexes when you compress columns with btree indexes.
- Vectorize filters in the WHERE clause that contain text equality operators and LIKE expressions.
To learn more, see the TimescaleDB release notes.
🔍 Database Audit Logging with pgaudit
May 31, 2024
The Postgres Audit extension(pgaudit) is now available on [Timescale Cloud][signup]. pgaudit provides detailed database session and object audit logging in the Timescale Cloud logs.
If you have strict security and compliance requirements and need to log all operations on the database level, pgaudit can help. You can also export these audit logs to Amazon CloudWatch.
To learn more, see the pgaudit documentation.
🌡 International System of Unit Support with postgresql-unit
May 31, 2024
The SI Units for Postgres extension(unit) provides support for the ISU in [Timescale Cloud][signup].
You can use Timescale Cloud to solve day-to-day questions. For example, to see what 50°C is in °F, run the following query in your Timescale Cloud service:
To learn more, see the postgresql-unit documentation.
===== PAGE: https://docs.tigerdata.com/about/timescaledb-editions/ =====
Examples:
Example 1 (unknown):
SELECT * FROM hypertable WHERE timestamp_col > now() - '100 days'::interval
Example 2 (unknown):
begin;
insert into users (name, email) values ('john doe', 'john@example.com');
abort; -- nothing inserted
Example 3 (unknown):
create temporary table temp_users (email text);
insert into temp_sales (email) values ('john@example.com');
-- table will automatically disappear after your session ends
Example 4 (unknown):
set search_path to 'myschema', 'public';
Create a compression policy
URL: llms-txt#create-a-compression-policy
Contents:
- Enable a compression policy
- Enabling compression
- View current compression policy
- Pause compression policy
- Remove compression policy
- Disable compression
Old API since TimescaleDB v2.18.0 Replaced by Optimize your data for real-time analytics.
You can enable compression on individual hypertables, by declaring which column you want to segment by.
Enable a compression policy
This page uses an example table, called example, and segments it by the
device_id column. Every chunk that is more than seven days old is then marked
to be automatically compressed. The source data is organized like this:
|time|device_id|cpu|disk_io|energy_consumption| |-|-|-|-|-| |8/22/2019 0:00|1|88.2|20|0.8| |8/22/2019 0:05|2|300.5|30|0.9|
Enabling compression
At the
psqlprompt, alter the table:Add a compression policy to compress chunks that are older than seven days:
For more information, see the API reference for
[ALTER TABLE (compression)][alter-table-compression] and
[add_compression_policy][add_compression_policy].
View current compression policy
To view the compression policy that you've set:
For more information, see the API reference for [timescaledb_information.jobs][timescaledb_information-jobs].
Pause compression policy
To disable a compression policy temporarily, find the corresponding job ID and then call alter_job to pause it:
Remove compression policy
To remove a compression policy, use remove_compression_policy:
For more information, see the API reference for
[remove_compression_policy][remove_compression_policy].
Disable compression
You can disable compression entirely on individual hypertables. This command works only if you don't currently have any compressed chunks:
If your hypertable contains compressed chunks, you need to [decompress each chunk][decompress-chunks] individually before you can turn off compression.
===== PAGE: https://docs.tigerdata.com/use-timescale/compression/modify-compressed-data/ =====
Examples:
Example 1 (sql):
ALTER TABLE example SET (
timescaledb.compress,
timescaledb.compress_segmentby = 'device_id'
);
Example 2 (sql):
SELECT add_compression_policy('example', INTERVAL '7 days');
Example 3 (sql):
SELECT * FROM timescaledb_information.jobs
WHERE proc_name='policy_compression';
Example 4 (sql):
SELECT * FROM timescaledb_information.jobs where proc_name = 'policy_compression' AND relname = 'example'
Compress your data using hypercore
URL: llms-txt#compress-your-data-using-hypercore
Contents:
- Optimize your data in the columnstore
- Take advantage of query speedups
Over time you end up with a lot of data. Since this data is mostly immutable, you can compress it to save space and avoid incurring additional cost.
TimescaleDB is built for handling event-oriented data such as time-series and fast analytical queries, it comes with support of [hypercore][hypercore] featuring the columnstore.
[Hypercore][hypercore] enables you to store the data in a vastly more efficient format allowing up to 90x compression ratio compared to a normal Postgres table. However, this is highly dependent on the data and configuration.
[Hypercore][hypercore] is implemented natively in Postgres and does not require special storage formats. When you convert your data from the rowstore to the columnstore, TimescaleDB uses Postgres features to transform the data into columnar format. The use of a columnar format allows a better compression ratio since similar data is stored adjacently. For more details on the columnar format, see [hypercore][hypercore].
A beneficial side effect of compressing data is that certain queries are significantly faster, since less data has to be read into memory.
Optimize your data in the columnstore
To compress the data in the transactions table, do the following:
- Connect to your Tiger Cloud service
In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed. You can also connect to your service using [psql][connect-using-psql].
- Convert data to the columnstore:
You can do this either automatically or manually:
[Automatically convert chunks][add_columnstore_policy] in the hypertable to the columnstore at a specific time interval:
[Manually convert all chunks][convert_to_columnstore] in the hypertable to the columnstore:
Take advantage of query speedups
Previously, data in the columnstore was segmented by the block_id column value.
This means fetching data by filtering or grouping on that column is
more efficient. Ordering is set to time descending. This means that when you run queries
which try to order data in the same way, you see performance benefits.
- Connect to your Tiger Cloud service
In [Tiger Cloud Console][services-portal] open an [SQL editor][in-console-editors]. The in-Console editors display the query speed.
- Run the following query:
Performance speedup is of two orders of magnitude, around 15 ms when compressed in the columnstore and 1 second when decompressed in the rowstore.
===== PAGE: https://docs.tigerdata.com/tutorials/blockchain-query/blockchain-dataset/ =====
Examples:
Example 1 (sql):
CALL add_columnstore_policy('transactions', after => INTERVAL '1d');
Example 2 (sql):
DO $$
DECLARE
chunk_name TEXT;
BEGIN
FOR chunk_name IN (SELECT c FROM show_chunks('transactions') c)
LOOP
RAISE NOTICE 'Converting chunk: %', chunk_name; -- Optional: To see progress
CALL convert_to_columnstore(chunk_name);
END LOOP;
RAISE NOTICE 'Conversion to columnar storage complete for all chunks.'; -- Optional: Completion message
END$$;
Example 3 (sql):
WITH recent_blocks AS (
SELECT block_id FROM transactions
WHERE is_coinbase IS TRUE
ORDER BY time DESC
LIMIT 5
)
SELECT
t.block_id, count(*) AS transaction_count,
SUM(weight) AS block_weight,
SUM(output_total_usd) AS block_value_usd
FROM transactions t
INNER JOIN recent_blocks b ON b.block_id = t.block_id
WHERE is_coinbase IS NOT TRUE
GROUP BY t.block_id;
ALTER TABLE (Compression)
URL: llms-txt#alter-table-(compression)
Contents:
- Samples
- Required arguments
- Optional arguments
- Parameters
Old API since TimescaleDB v2.18.0 Replaced by ALTER TABLE (Hypercore).
'ALTER TABLE' statement is used to turn on compression and set compression options.
By itself, this ALTER statement alone does not compress a hypertable. To do so, either create a
compression policy using the [add_compression_policy][add_compression_policy] function or manually
compress a specific hypertable chunk using the [compress_chunk][compress_chunk] function.
Configure a hypertable that ingests device data to use compression. Here, if the hypertable
is often queried about a specific device or set of devices, the compression should be
segmented using the device_id for greater performance.
You can also specify compressed chunk interval without changing other compression settings:
To disable the previously set option, set the interval to 0:
Required arguments
|Name|Type|Description|
|-|-|-|
|timescaledb.compress|BOOLEAN|Enable or disable compression|
Optional arguments
|Name|Type| Description |
|-|-|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|timescaledb.compress_orderby|TEXT| Order used by compression, specified in the same way as the ORDER BY clause in a SELECT query. The default is the descending order of the hypertable's time column. |
|timescaledb.compress_segmentby|TEXT| Column list on which to key the compressed segments. An identifier representing the source of the data such as device_id or tags_id is usually a good candidate. The default is no segment by columns. |
|timescaledb.compress_chunk_time_interval|TEXT| EXPERIMENTAL: Set compressed chunk time interval used to roll chunks into. This parameter compresses every chunk, and then irreversibly merges it into a previous adjacent chunk if possible, to reduce the total number of chunks in the hypertable. Note that chunks will not be split up during decompression. It should be set to a multiple of the current chunk interval. This option can be changed independently of other compression settings and does not require the timescaledb.compress argument. |
|Name|Type|Description|
|-|-|-|
|table_name|TEXT|Hypertable that supports compression|
|column_name|TEXT|Column used to order by or segment by|
|interval|TEXT|Time interval used to roll compressed chunks into|
===== PAGE: https://docs.tigerdata.com/api/compression/hypertable_compression_stats/ =====
Examples:
Example 1 (unknown):
## Samples
Configure a hypertable that ingests device data to use compression. Here, if the hypertable
is often queried about a specific device or set of devices, the compression should be
segmented using the `device_id` for greater performance.
Example 2 (unknown):
You can also specify compressed chunk interval without changing other
compression settings:
Example 3 (unknown):
To disable the previously set option, set the interval to 0:
FAQ and troubleshooting
URL: llms-txt#faq-and-troubleshooting
Contents:
- Unsupported in live migration
- Where can I find logs for processes running during live migration?
- Source and target databases have different TimescaleDB versions
- Why does live migration log "no tuple identifier" warning?
- Set REPLICA IDENTITY on Postgres partitioned tables
- Can I use read/failover replicas as source database for live migration?
- Can I use live migration with a Postgres connection pooler like PgBouncer?
- Can I use Tiger Cloud instance as source for live migration?
- How can I exclude a schema/table from being replicated in live migration?
- Large migrations blocked
Unsupported in live migration
Live migration tooling is currently experimental. You may run into the following shortcomings:
- Live migration does not yet support mutable columnstore compression (
INSERT,UPDATE,DELETEon data in the columnstore). - By default, numeric fields containing
NaN/+Inf/-Infvalues are not correctly replicated, and will be converted toNULL. A workaround is available, but is not enabled by default.
Should you run into any problems, please open a support request before losing any time debugging issues. You can open a support request directly from [Tiger Cloud Console][support-link], or by email to support@tigerdata.com.
Where can I find logs for processes running during live migration?
Live migration involves several background processes to manage different stages of
the migration. The logs of these processes can be helpful for troubleshooting
unexpected behavior. You can find these logs in the <volume_mount>/logs directory.
Source and target databases have different TimescaleDB versions
When you migrate a [self-hosted][self hosted] or [Managed Service for TimescaleDB (MST)][mst] database to Tiger Cloud, the source database and the destination [Tiger Cloud service][timescale-service] must run the same version of TimescaleDB.
Before you start [live migration][live migration]:
Check the version of TimescaleDB running on the source database and the target Tiger Cloud service:
If the version of TimescaleDB on the source database is lower than your Tiger Cloud service, either:
- Downgrade: reinstall an older version of TimescaleDB on your Tiger Cloud service that matches the source database:
Connect to your Tiger Cloud service and check the versions of TimescaleDB available:
If an available TimescaleDB release matches your source database:
Uninstall TimescaleDB from your Tiger Cloud service:
Reinstall the correct version of TimescaleDB:
You may need to reconnect to your Tiger Cloud service using psql -X when you're creating the TimescaleDB extension.
- Upgrade: for self-hosted databases, [upgrade TimescaleDB][self hosted upgrade] to match your Tiger Cloud service.
Why does live migration log "no tuple identifier" warning?
Live migration logs a warning WARNING: no tuple identifier for UPDATE in table
when it cannot determine which specific rows should be updated after receiving an
UPDATE statement from the source database during replication. This occurs when tables
in the source database that receive UPDATE statements lack either a PRIMARY KEY or
a REPLICA IDENTITY setting. For live migration to successfully replicate UPDATE and
DELETE statements, tables must have either a PRIMARY KEY or REPLICA IDENTITY set
as a prerequisite.
Set REPLICA IDENTITY on Postgres partitioned tables
If your Postgres tables use native partitioning, setting REPLICA IDENTITY on the
root (parent) table will not automatically apply it to the partitioned child tables.
You must manually set REPLICA IDENTITY on each partitioned child table.
Can I use read/failover replicas as source database for live migration?
Live migration does not support replication from read or failover replicas. You must provide a connection string that points directly to your source database for live migration.
Can I use live migration with a Postgres connection pooler like PgBouncer?
Live migration does not support connection poolers. You must provide a connection string that points directly to your source and target databases for live migration to work smoothly.
Can I use Tiger Cloud instance as source for live migration?
No, Tiger Cloud cannot be used as a source database for live migration.
How can I exclude a schema/table from being replicated in live migration?
At present, live migration does not allow for excluding schemas or tables from
replication, but this feature is expected to be added in future releases.
However, a workaround is available for skipping table data using the --skip-table-data flag.
For more information, please refer to the help text under the migrate subcommand.
Large migrations blocked
Tiger Cloud automatically manages the underlying disk volume. Due to
platform limitations, it is only possible to resize the disk once every six
hours. Depending on the rate at which you're able to copy data, you may be
affected by this restriction. Affected instances are unable to accept new data
and error with: FATAL: terminating connection due to administrator command.
If you intend on migrating more than 400 GB of data to Tiger Cloud, open a support request requesting the required storage to be pre-allocated in your Tiger Cloud service.
You can open a support request directly from [Tiger Cloud Console][support-link], or by email to support@tigerdata.com.
When pg_dump starts, it takes an ACCESS SHARE lock on all tables which it
dumps. This ensures that tables aren't dropped before pg_dump is able to drop
them. A side effect of this is that any query which tries to take an
ACCESS EXCLUSIVE lock on a table is be blocked by the ACCESS SHARE lock.
A number of Tiger Cloud-internal processes require taking ACCESS EXCLUSIVE
locks to ensure consistency of the data. The following is a non-exhaustive list
of potentially affected operations:
- converting a chunk into the columnstore/rowstore and back
- continuous aggregate refresh (before 2.12)
- create hypertable with foreign keys, truncate hypertable
- enable hypercore on a hypertable
- drop chunks
The most likely impact of the above is that background jobs for retention
policies, columnstore compression policies, and continuous aggregate refresh policies are
blocked for the duration of the pg_dump command. This may have unintended
consequences for your database performance.
Dumping with concurrency
When using the pg_dump directory format, it is possible to use concurrency to
use multiple connections to the source database to dump data. This speeds up
the dump process. Due to the fact that there are multiple connections, it is
possible for pg_dump to end up in a deadlock situation. When it detects a
deadlock it aborts the dump.
In principle, any query which takes an ACCESS EXCLUSIVE lock on a table
causes such a deadlock. As mentioned above, some common operations which take
an ACCESS EXCLUSIVE lock are:
- retention policies
- columnstore compression policies
- continuous aggregate refresh policies
If you would like to use concurrency nonetheless, turn off all background jobs
in the source database before running pg_dump, and turn them on once the dump
is complete. If the dump procedure takes longer than the continuous aggregate
refresh policy's window, you must manually refresh the continuous aggregate in
the correct time range. For more information, consult the
[refresh policies documentation].
To turn off the jobs:
Restoring with concurrency
If the directory format is used for pg_dump and pg_restore, concurrency can be
employed to speed up the process. Unfortunately, loading the tables in the
timescaledb_catalog schema concurrently causes errors. Furthermore, the
tsdbadmin user does not have sufficient privileges to turn off triggers in
this schema. To get around this limitation, load this schema serially, and then
load the rest of the database concurrently.
Ownership of background jobs
The _timescaledb_config.bgw_jobs table is used to manage background jobs.
This includes custom jobs, columnstore compression policies, retention
policies, and continuous aggregate refresh policies. On Tiger Cloud, this table
has a trigger which ensures that no database user can create or modify jobs
owned by another database user. This trigger can provide an obstacle for migrations.
If the --no-owner flag is used with pg_dump and pg_restore, all
objects in the target database are owned by the user that ran
pg_restore, likely tsdbadmin.
If all the background jobs in the source database were owned by a user of the
same name as the user running the restore (again likely tsdbadmin), then
loading the _timescaledb_config.bgw_jobs table should work.
If the background jobs in the source were owned by the postgres user, they
are be automatically changed to be owned by the tsdbadmin user. In this case,
one just needs to verify that the jobs do not make use of privileges that the
tsdbadmin user does not possess.
If background jobs are owned by one or more users other than the user
employed in restoring, then there could be issues. To work around this
issue, do not dump this table with pg_dump. Provide either
--exclude-table-data='_timescaledb_config.bgw_job' or
--exclude-table='_timescaledb_config.bgw_job' to pg_dump to skip
this table. Then, use psql and the COPY command to dump and
restore this table with modified values for the owner column.
Once the table has been loaded and the restore completed, you may then use SQL to adjust the ownership of the jobs and/or the associated stored procedures and functions as you wish.
Extension availability
There are a vast number of Postgres extensions available in the wild. Tiger Cloud supports many of the most popular extensions, but not all extensions. Before migrating, check that the extensions you are using are supported on Tiger Cloud. Consult the [list of supported extensions].
TimescaleDB extension in the public schema
When self-hosting, the TimescaleDB extension may be installed in an arbitrary
schema. Tiger Cloud only supports installing the TimescaleDB extension in the
public schema. How to go about resolving this depends heavily on the
particular details of the source schema and the migration approach chosen.
Tiger Cloud does not support using custom tablespaces. Providing the
--no-tablespaces flag to pg_dump and pg_restore when
dumping/restoring the schema results in all objects being in the
default tablespace as desired.
Only one database per instance
While Postgres clusters can contain many databases, Tiger Cloud services are limited to a single database. When migrating a cluster with multiple databases to Tiger Cloud, one can either migrate each source database to a separate Tiger Cloud service or "merge" source databases to target schemas.
Superuser privileges
The tsdbadmin database user is the most powerful available on Tiger Cloud, but it
is not a true superuser. Review your application for use of superuser privileged
operations and mitigate before migrating.
Migrate partial continuous aggregates
In order to improve the performance and compatibility of continuous aggregates, TimescaleDB v2.7 replaces partial continuous aggregates with finalized continuous aggregates.
To test your database for partial continuous aggregates, run the following query:
If you have partial continuous aggregates in your database, [migrate them][migrate] from partial to finalized before you migrate your database.
If you accidentally migrate partial continuous aggregates across Postgres versions, you see the following error when you query any continuous aggregates:
===== PAGE: https://docs.tigerdata.com/ai/mcp-server/ =====
Examples:
Example 1 (sql):
select extversion from pg_extension where extname = 'timescaledb';
Example 2 (sql):
SELECT version FROM pg_available_extension_versions WHERE name = 'timescaledb' ORDER BY 1 DESC;
Example 3 (sql):
DROP EXTENSION timescaledb;
Example 4 (sql):
CREATE EXTENSION timescaledb VERSION '<version>';
Energy consumption data tutorial - set up compression
URL: llms-txt#energy-consumption-data-tutorial---set-up-compression
Contents:
- Compression setup
- Add a compression policy
- Taking advantage of query speedups
You have now seen how to create a hypertable for your energy consumption dataset and query it. When ingesting a dataset like this is seldom necessary to update old data and over time the amount of data in the tables grows. Over time you end up with a lot of data and since this is mostly immutable you can compress it to save space and avoid incurring additional cost.
It is possible to use disk-oriented compression like the support offered by ZFS and Btrfs but since TimescaleDB is build for handling event-oriented data (such as time-series) it comes with support for compressing data in hypertables.
TimescaleDB compression allows you to store the data in a vastly more efficient format allowing up to 20x compression ratio compared to a normal Postgres table, but this is of course highly dependent on the data and configuration.
TimescaleDB compression is implemented natively in Postgres and does not require special storage formats. Instead it relies on features of Postgres to transform the data into columnar format before compression. The use of a columnar format allows better compression ratio since similar data is stored adjacently. For more details on how the compression format looks, you can look at the [compression design][compression-design] section.
A beneficial side-effect of compressing data is that certain queries are significantly faster since less data has to be read into memory.
- Connect to the Tiger Cloud service that contains the energy
dataset using, for example
psql. - Enable compression on the table and pick suitable segment-by and
order-by column using the
ALTER TABLEcommand:
Depending on the choice if segment-by and order-by column you can
get very different performance and compression ratio. To learn
more about how to pick the correct columns, see
[here][segment-by-columns].
You can manually compress all the chunks of the hypertable using
compress_chunkin this manner:You can also [automate compression][automatic-compression] by adding a [compression policy][add_compression_policy] which will be covered below.
Now that you have compressed the table you can compare the size of the dataset before and after compression:
This shows a significant improvement in data usage:
Add a compression policy
To avoid running the compression step each time you have some data to compress you can set up a compression policy. The compression policy allows you to compress data that is older than a particular age, for example, to compress all chunks that are older than 8 days:
Compression policies run on a regular schedule, by default once every day, which means that you might have up to 9 days of uncompressed data with the setting above.
You can find more information on compression policies in the [add_compression_policy][add_compression_policy] section.
Taking advantage of query speedups
Previously, compression was set up to be segmented by type_id column value.
This means fetching data by filtering or grouping on that column will be
more efficient. Ordering is also set to created descending so if you run queries
which try to order data with that ordering, you should see performance benefits.
For instance, if you run the query example from previous section:
You should see a decent performance difference when the dataset is compressed and when is decompressed. Try it yourself by running the previous query, decompressing the dataset and running it again while timing the execution time. You can enable timing query times in psql by running:
To decompress the whole dataset, run:
On an example setup, speedup performance observed was an order of magnitude, 30 ms when compressed vs 360 ms when decompressed.
Try it yourself and see what you get!
===== PAGE: https://docs.tigerdata.com/tutorials/financial-ingest-real-time/financial-ingest-dataset/ =====
Examples:
Example 1 (sql):
ALTER TABLE metrics
SET (
timescaledb.compress,
timescaledb.compress_segmentby='type_id',
timescaledb.compress_orderby='created DESC'
);
Example 2 (sql):
SELECT compress_chunk(c) from show_chunks('metrics') c;
Example 3 (sql):
SELECT
pg_size_pretty(before_compression_total_bytes) as before,
pg_size_pretty(after_compression_total_bytes) as after
FROM hypertable_compression_stats('metrics');
Example 4 (sql):
before | after
--------+-------
180 MB | 16 MB
(1 row)
Tuple decompression limit exceeded by operation
URL: llms-txt#tuple-decompression-limit-exceeded-by-operation
When inserting, updating, or deleting tuples from chunks in the columnstore, it might be necessary to convert tuples to the rowstore. This happens either when you are updating existing tuples or have constraints that need to be verified during insert time. If you happen to trigger a lot of rowstore conversion with a single command, you may end up running out of storage space. For this reason, a limit has been put in place on the number of tuples you can decompress into the rowstore for a single command.
The limit can be increased or turned off (set to 0) like so:
===== PAGE: https://docs.tigerdata.com/_troubleshooting/caggs-queries-fail/ =====
Examples:
Example 1 (sql):
-- set limit to a milion tuples
SET timescaledb.max_tuples_decompressed_per_dml_transaction TO 1000000;
-- disable limit by setting to 0
SET timescaledb.max_tuples_decompressed_per_dml_transaction TO 0;
Schema modifications
URL: llms-txt#schema-modifications
Contents:
- Add a nullable column
- Add a column with a default value and a NOT NULL constraint
- Rename a column
- Drop a column
You can modify the schema of compressed hypertables in recent versions of TimescaleDB.
|Schema modification|Before TimescaleDB 2.1|TimescaleDB 2.1 to 2.5|TimescaleDB 2.6 and above|
|-|-|-|-|
|Add a nullable column|❌|✅|✅|
|Add a column with a default value and a NOT NULL constraint|❌|❌|✅|
|Rename a column|❌|✅|✅|
|Drop a column|❌|❌|✅|
|Change the data type of a column|❌|❌|❌|
To perform operations that aren't supported on compressed hypertables, first [decompress][decompression] the table.
Add a nullable column
To add a nullable column:
Note that adding constraints to the new column is not supported before TimescaleDB v2.6.
Add a column with a default value and a NOT NULL constraint
To add a column with a default value and a not-null constraint:
You can drop a column from a compressed hypertable, if the column is not an
orderby or segmentby column. To drop a column:
===== PAGE: https://docs.tigerdata.com/use-timescale/compression/decompress-chunks/ =====
Examples:
Example 1 (sql):
ALTER TABLE <hypertable> ADD COLUMN <column_name> <datatype>;
Example 2 (sql):
ALTER TABLE conditions ADD COLUMN device_id integer;
Example 3 (sql):
ALTER TABLE <hypertable> ADD COLUMN <column_name> <datatype>
NOT NULL DEFAULT <default_value>;
Example 4 (sql):
ALTER TABLE conditions ADD COLUMN device_id integer
NOT NULL DEFAULT 1;
Compression
URL: llms-txt#compression
Contents:
- Restrictions
Old API since TimescaleDB v2.18.0 Replaced by Hypercore.
Compression functionality is included in Hypercore.
Before you set up compression, you need to [configure the hypertable for compression][configure-compression] and then [set up a compression policy][add_compression_policy].
Before you set up compression for the first time, read the compression blog post and documentation.
You can also [compress chunks manually][compress_chunk], instead of using an automated compression policy to compress chunks as they age.
Compressed chunks have the following limitations:
ROW LEVEL SECURITYis not supported on compressed chunks.- Creation of unique constraints on compressed chunks is not supported. You can add them by disabling compression on the hypertable and re-enabling after constraint creation.
In general, compressing a hypertable imposes some limitations on the types of data modifications that you can perform on data inside a compressed chunk.
This table shows changes to the compression feature, added in different versions of TimescaleDB:
|TimescaleDB version|Supported data modifications on compressed chunks| |-|-| |1.5 - 2.0|Data and schema modifications are not supported.| |2.1 - 2.2|Schema may be modified on compressed hypertables. Data modification not supported.| |2.3|Schema modifications and basic insert of new data is allowed. Deleting, updating and some advanced insert statements are not supported.| |2.11|Deleting, updating and advanced insert statements are supported.|
In TimescaleDB 2.1 and later, you can modify the schema of hypertables that have compressed chunks. Specifically, you can add columns to and rename existing columns of compressed hypertables.
In TimescaleDB v2.3 and later, you can insert data into compressed chunks and to enable compression policies on distributed hypertables.
In TimescaleDB v2.11 and later, you can update and delete compressed data.
You can also use advanced insert statements like ON CONFLICT and RETURNING.
===== PAGE: https://docs.tigerdata.com/api/distributed-hypertables/ =====